起源自 AstrBot 项目群里有人问为什么 AstrBot 又又又又项目检查更新失败:
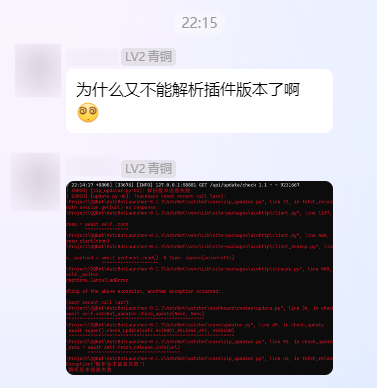
当时由于正在忙其他事,就随便回了一个“因为直接请求 GitHub” 因此可能有时会有这个问题。
过了一会,突然想到我已经将检查更新的业务切到自己的服务上了:api.soulter.top。于是自己打开看了看:
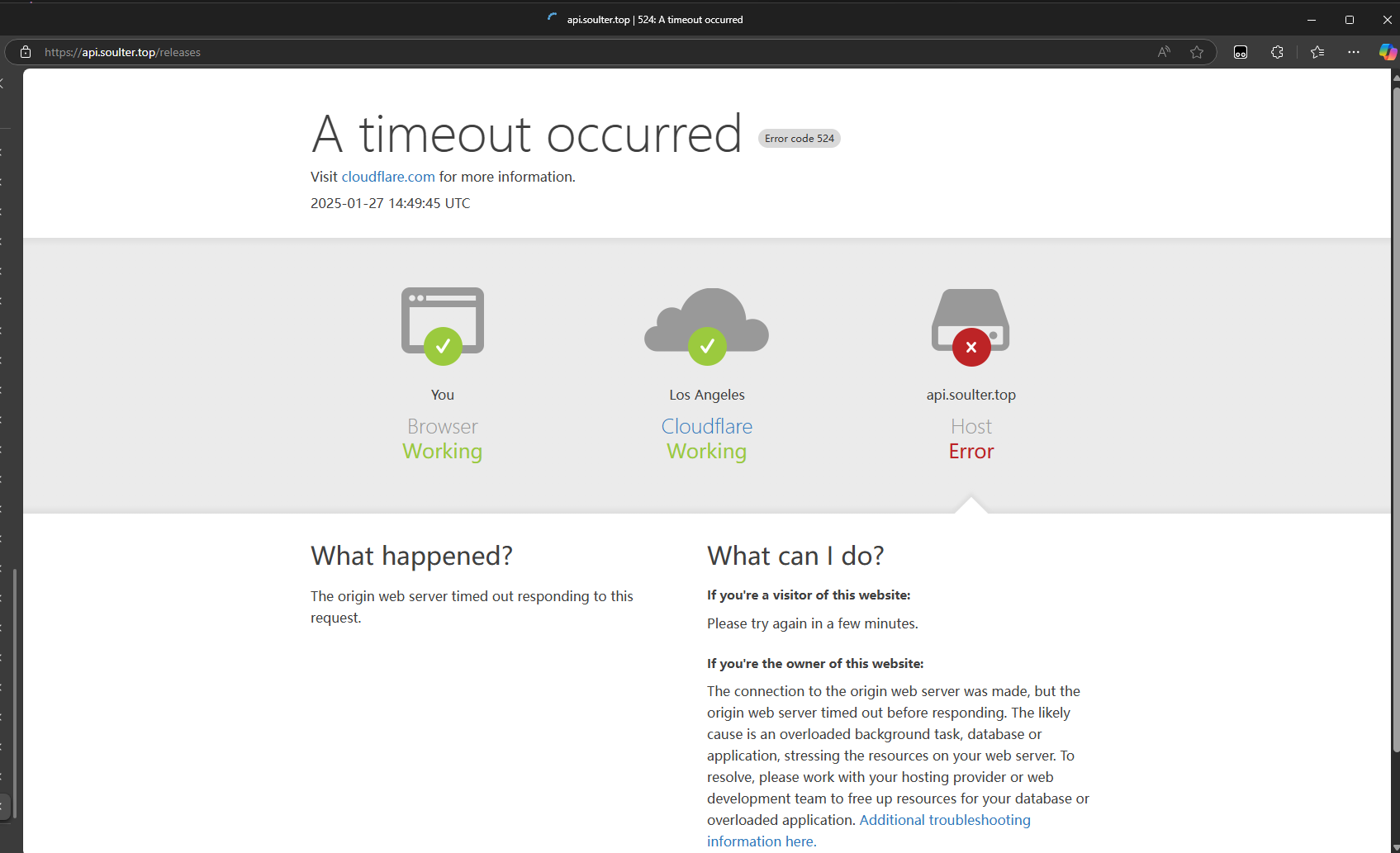
不对劲。然后赶紧登服务器查看情况。由于在老家,网络巨差,4G 网络的带宽大概在 100Kbps - 1.3Mbps 条跳跃,并且丢包率严重,因此 ssh 到我洛杉矶的服务器的体验简直就是和地球人操作火星上的火星车一样的痛苦。
甚至无法测速。
艰难地用 tmux 切换到 API 服务,发现已经卡死无响应,于是马上 kill 掉这个服务重启,然后正常了。
开 top 看了看进程情况,发现 postgres 占用的 CPU 时间异常的高。由于机器上只有 tickstats 在用 timescaleDB(基于 pg 的一个时序数据库),因此马上查看 tickstats Docker 容器的 logs,发现最近的 POST 请求全部报 400。
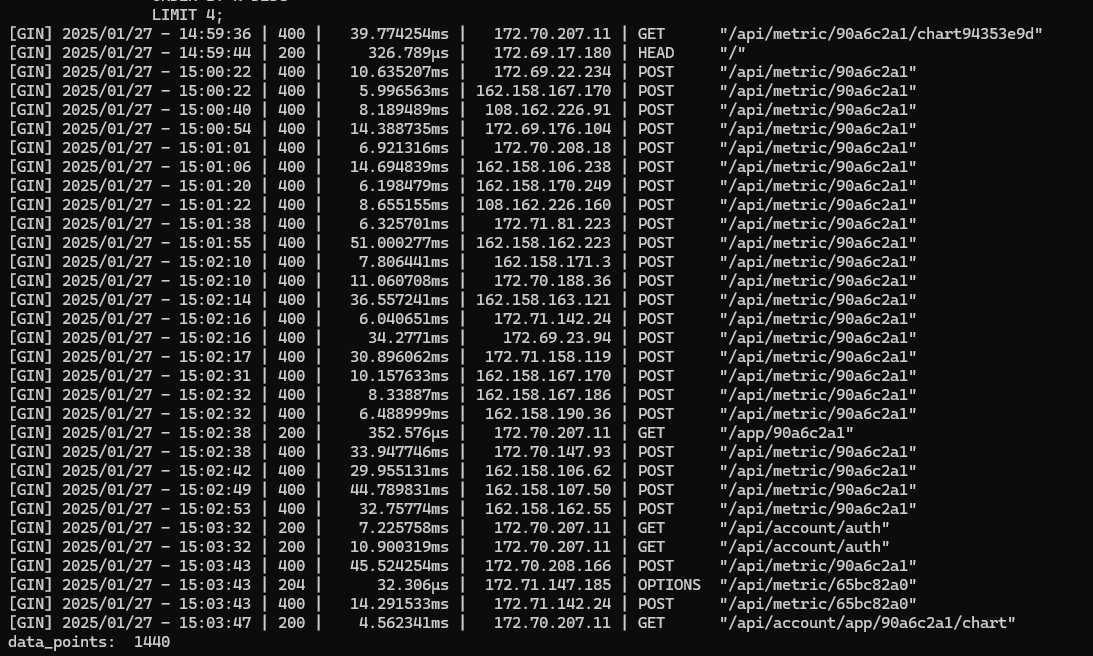
结合 PG 的异常占用,我又马上切到了 timescaleDB 的日志:
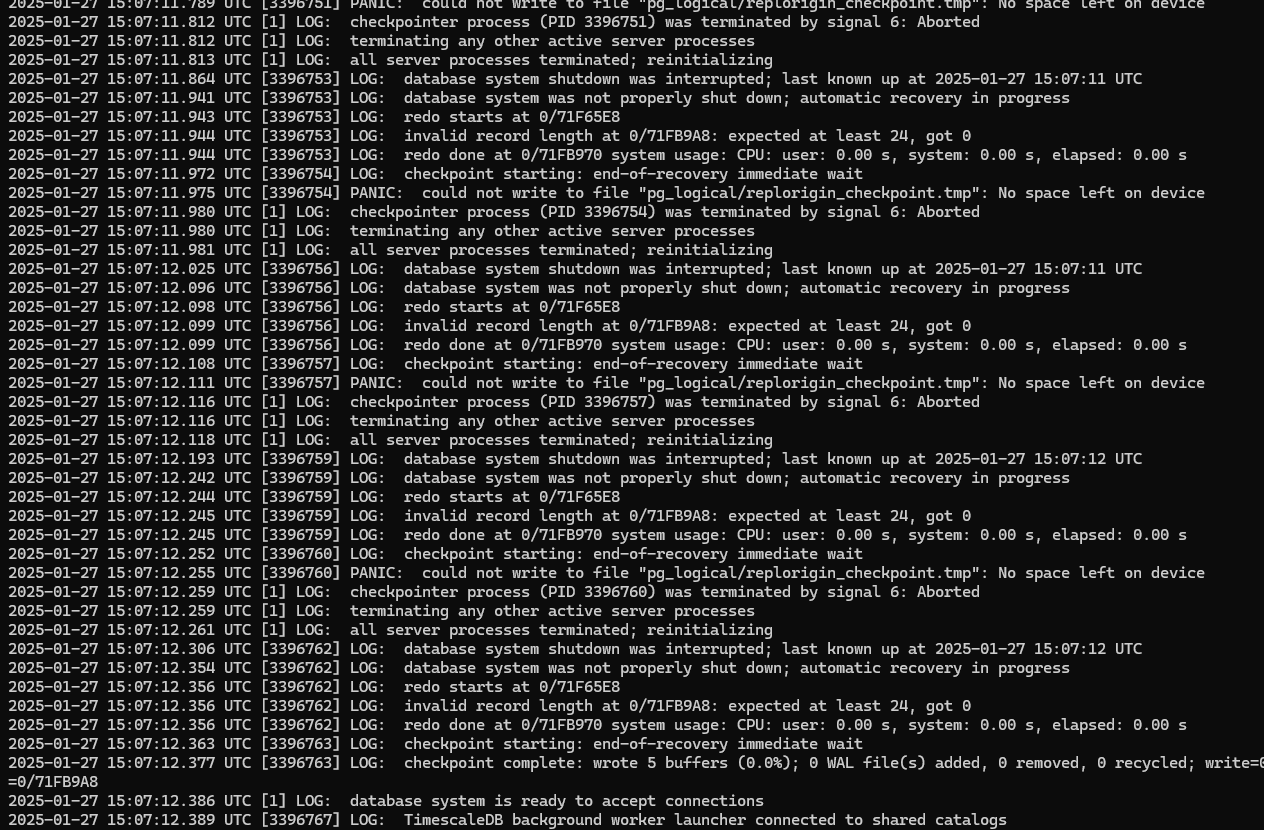
噔噔咚!NO SPACE LEFT ON DEVICE!
于是 df -h 一看,好家伙:
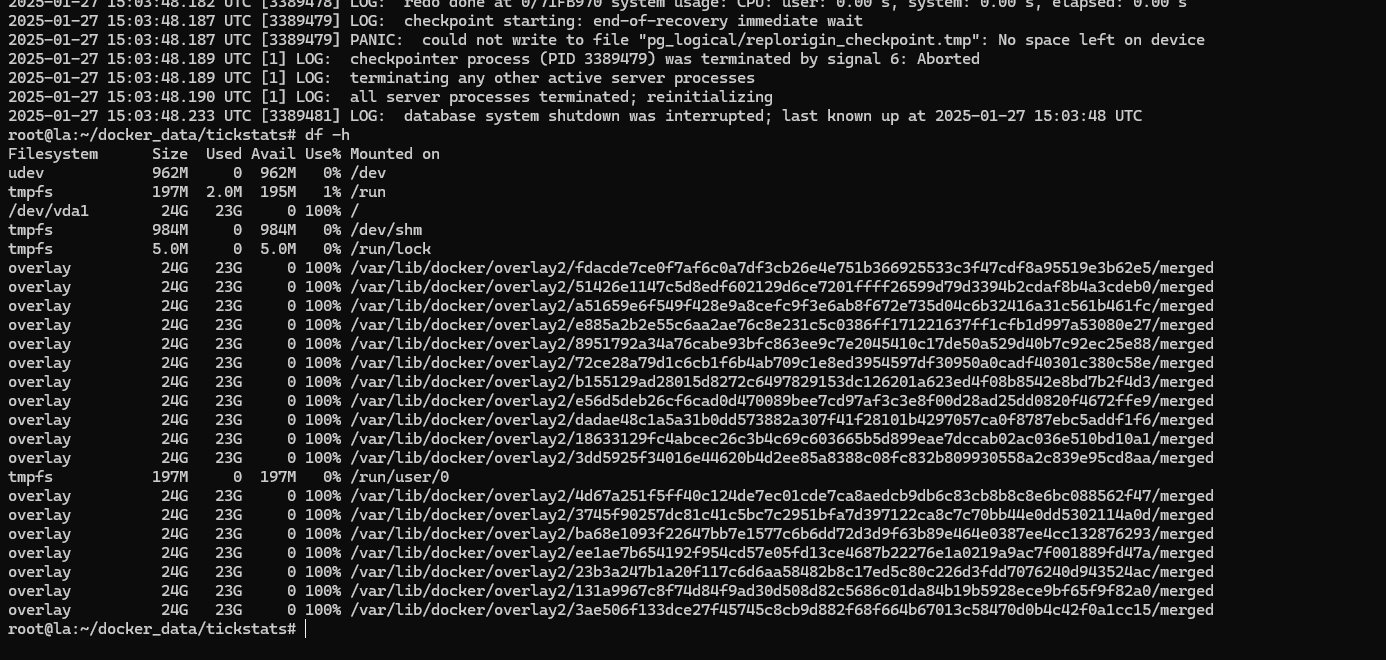
想到最快能解决存储空间问题的只有强制删除掉一些 Docker 镜像,于是 docker images 一看:
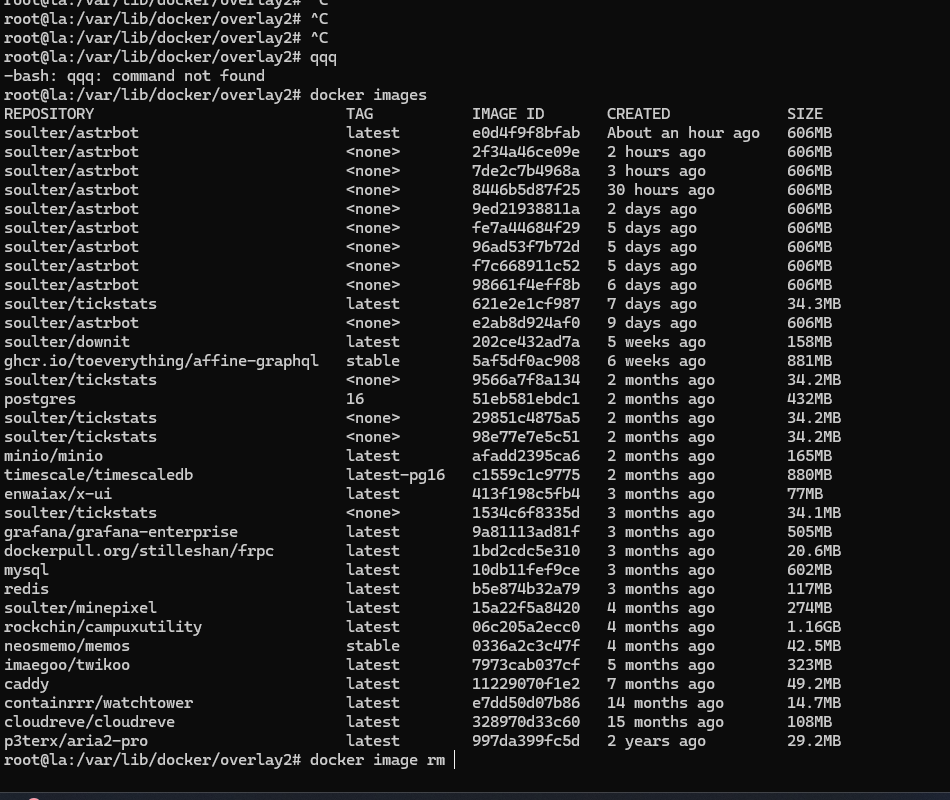
好家伙,原来是 WatchTower 在自动更新镜像的时候没有删除掉旧的镜像,导致了磁盘空间不足。

最后手动清理旧镜像然后传递 --cleanup 给 WatchTower 之后解决了这个问题。
其实类似等级的“运维事故”每个月都会上演一两次,只不过今天…是 TMD 除夕的前一天的晚上十点半,而且我的网络环境巨差无比,出这个事情太搞了…
以及想起一个 meme…

今天给 AstrBot 发了一个 v3.4.14 版本,结果 issue 10分钟内就到达了战场,最后反工了两次…
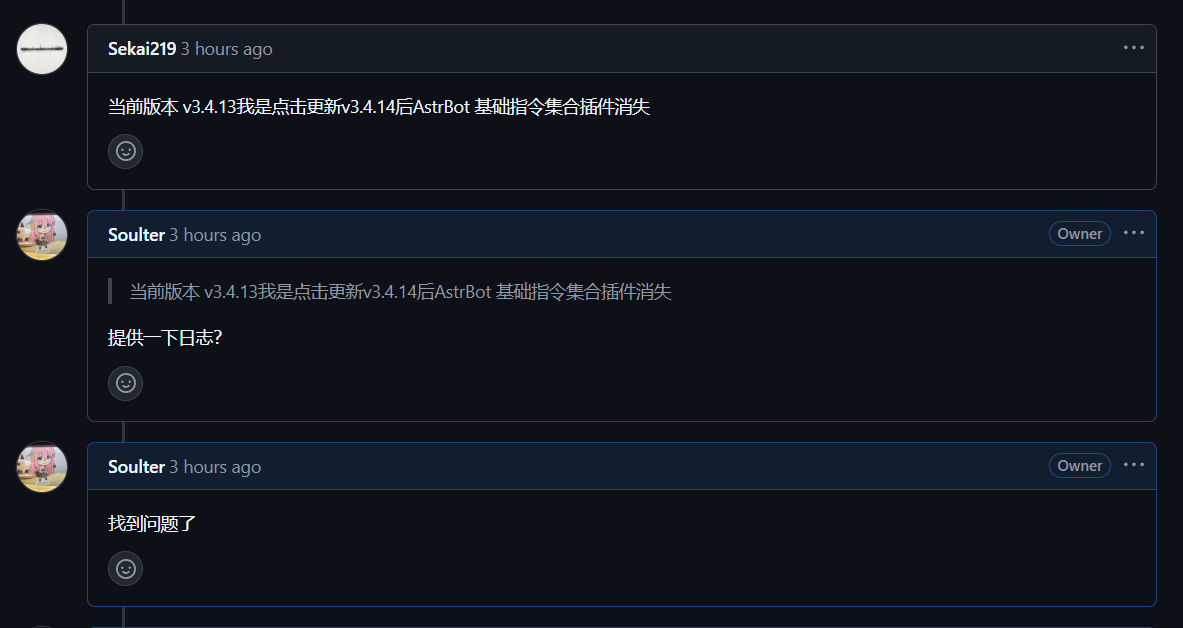
hummmmm…
1 | | ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄ ̄| |
