一些碎碎念
我维护 AstrBot 这个项目到现在已经有两年多的时间了。从 2022 年 12 月底 ChatGPT 问世以来,这个项目便在不断更迭,途中也收获了不少的用户和他们的支持。这是我目前为止花费时间和精力最多的一个项目,包括设计整个架构项目、维护项目等等。然而,我却没有将这些思考过程以文章的形式写下来。
在这个项目正式被遗忘在时间的洪流之前,我觉得非常有必要写几篇文章来好好梳理一下它,来让更多人知道它背后的故事(聊聊它是怎么从一个几十行的代码膨胀到现在将近一万六千行代码的x)。毕竟真正去看源代码、看 commit log 的人应该没有多少吧。
@z2z63 的一句话很好:“源代码是设计的编译产物,通过读源代码去理解设计就好比反汇编”。接触了这么多语言和项目,我越来越体会到架构设计的重要性。好的架构设计将导致一致的系统实现,更好的可维护性和可扩展性。而坏的设计会导致不良的代码,系统实现没有弹性,不能适应变化,模块间匹配得不好,重复的代码和工作在不同模块中随处可见。这招致在它上面叠加更多坏的设计(实际上就是它在迫使你这样做)。并且当想对代码进行单元测试的时候,发现由于高耦合的代码导致对某个模块进行单元测试成为了不可能。最终,开发者心情变差,没有良好的精神维护项目,就成了屎山。软件的架构设计不仅能影响最终软件的质量,甚至能够影响团队的组织结构。好的架构设计能够反映出好的团队分工,每个人/小团队负责某个模块,并且由于设计语言相通,对接和 Code Review 的效率也会提高。
同时,我也越来越感受到“软件工程没有银弹“这个道理。第一,任何一个设计都不可能完美应用于所有项目实现中。例如,一些设计思想倾向于对功能做高层次的封装以降低开发者的学习成本,而这带来的高抽象度可能会降低开发者对系统底层的控制,导致灵活性变差。这在 kernel 开发、嵌入式开发中是不可理喻的。再比如,Web 后端领域的微服务架构具有扩展性高、独立性强、高可用性等优点,但它如果用在某些原型项目、初创项目中就是徒增功耗、吕布骑狗。第二,对于一个需要应对动态变化的需求和环境的项目来说,没有一个设计是完美的。需求和环境变化本身就是一个难以预料的因素,没有一个“银弹”能够预见未来。频繁的功能迭代会让原本设计好的分层架构的边界变得模糊和松弛,最后引发下一次设计重构。
一个真正的工程师(任何领域)应该是善于解决问题的,解决问题的手段是灵活的,而不是教条地记住某些固定的看似高端的方法论便生搬硬套到每个问题中。
我本想用一篇文章讲述完所有内容,但是写到一半发现太难了,一篇文章难以完整阐述这两年的工作内容,因此我将它拆分成了几篇博客依次分享。
项目的早期
在这个项目的早期,其实只是为了将 OpenAI 发布的 ChatGPT 接入到 QQ 频道,根本没有考虑到如今 LLM 百家齐放的情况,也没想到要接入如此多的消息平台,QQ、微信、Telegram,甚至是小米音箱。于是结构非常简单:
- 一个调 OpenAI 接口的类
- 一个接收 QQ 频道事件的类
- 消息处理函数、机器人初始化函数等
消息处理函数、机器人初始化函数、接收频道事件的类等一些其他的工具函数都写在了 core.py 下,这个文件在后面一度达到了 1000 行。
随着 NewBing、逆向 ChatGPT 的出现,并且它们适用的机器人指令不相同,我开始注意到需要对项目进行分层了。
我将大语言模型提供商抽象为了 Provider 类,并创建 Command 类用于表示机器人指令,每一个大语言模型提供商都拥有一个 Command 子类。这样,只要配合配置文件选择使用不同的提供商,消息处理函数就可以很清晰地去调用它们。此外,在后面的更新中,为了接入 QQ 群,我还引入了 Platform 类,以表示不同的消息平台。
从这个阶段开始,我其实才真正对 OOP 有一个比较“清晰”的认识。
然而之后仍然遇到了各种各样的问题。举几个当时比较难缠的:
- (更新项目采用内置Git更新,用户无需调用 git pull,只需要输入
/update指令),由于配置文件直接写在 git 工作树中,当用户修改了配置文件,就会导致没办法 git pull,或者需要 --force,但这样的后果是一旦我更新了配置文件,就会导致更新后用户的配置文件被重置。这在当时一度成为非常棘手的问题以至于我尽可能不去更新配置文件。 - 指标上报、统计信息记录、初始化机器人、消息处理函数、各消息平台的启动函数、回复消息的函数、各平台的类都集成在了一个
core.py文件中,使得这个文件越来越臃肿,耦合度越来越高。 - 当前对于每一个消息事件的处理方式是新开一个线程进行处理。在多群聊的情况下,几乎每分钟都有几十个消息事件下发,也就是说每分钟都会新开几十个线程,非常吃资源。
项目设计的趋势
下面几点是在历经这几次大规模重构之后总结出的 AstrBot 的明显的设计方向。
简单可依赖
这是百度的一句 slogan,“简单” 和 “可依赖” 是小团队开发的核心准则,它们不仅提高开发效率,还降低了维护成本。人手越少越要以这个为执行标准,它带来的优势是双向的,既方便用户上手,也方便开发者维护。
软件架构不是一成不变的,要想做到随时可以修改,架构就必须简单,牺牲简单性的修改应当被抵制。形式永远服从功能,不要过度设计。
相关具体实践:
- 减少复杂的依赖链
- AstrBot 去除了 Git 更新功能,而直接采用压缩包下载源码的方式。
- 谨慎选择依赖库:引入第三方库前,明确其支持的系统架构(通过 pypi 查看
.whl覆盖度),避免因平台兼容性问题引发的 Bug。虽然 pip 支持源代码安装,但是还是不值得信任,因为有些库的源代码安装需要编译 C 代码,如果用户环境没有编译环境(比如 Windows 需要 Microsoft Visual C++ Build Tools),那么安装就会失败。
- 精简执行链路
- 每个流程的执行链路尽量短,保持函数、方法和类的单一职责。
- 避免业务逻辑过于复杂,确保每个功能模块清晰、直观。
- 简单的用户体验
- 一键式部署:优化部署流程,例如通过 Docker 容器化提供跨平台支持。
- 清晰的文档:提供简洁易懂的文档,降低上手门槛。
完全模块化
并且每个模块都应该有清晰的职责划分和限制的通信方式,实现高内聚和低耦合。模块化设计让功能可以独立开发、测试和部署,同时便于扩展和维护。
相关具体实践:
- 清晰的模块边界
- 插件化扩展
- 采取了注册机制扩展模块,如 Platform、Provider、Command、事件监听器皆可通过插件扩展。
- 松耦合设计
- 使用事件驱动架构或消息队列作为模块通信方式,避免模块之间的直接依赖。
更易读的代码
注释、docstrings、命名规则、PEP 8 规范、统一的设计风格等都是提高代码可读性的重要手段。
第一阶段——一个函数走天下
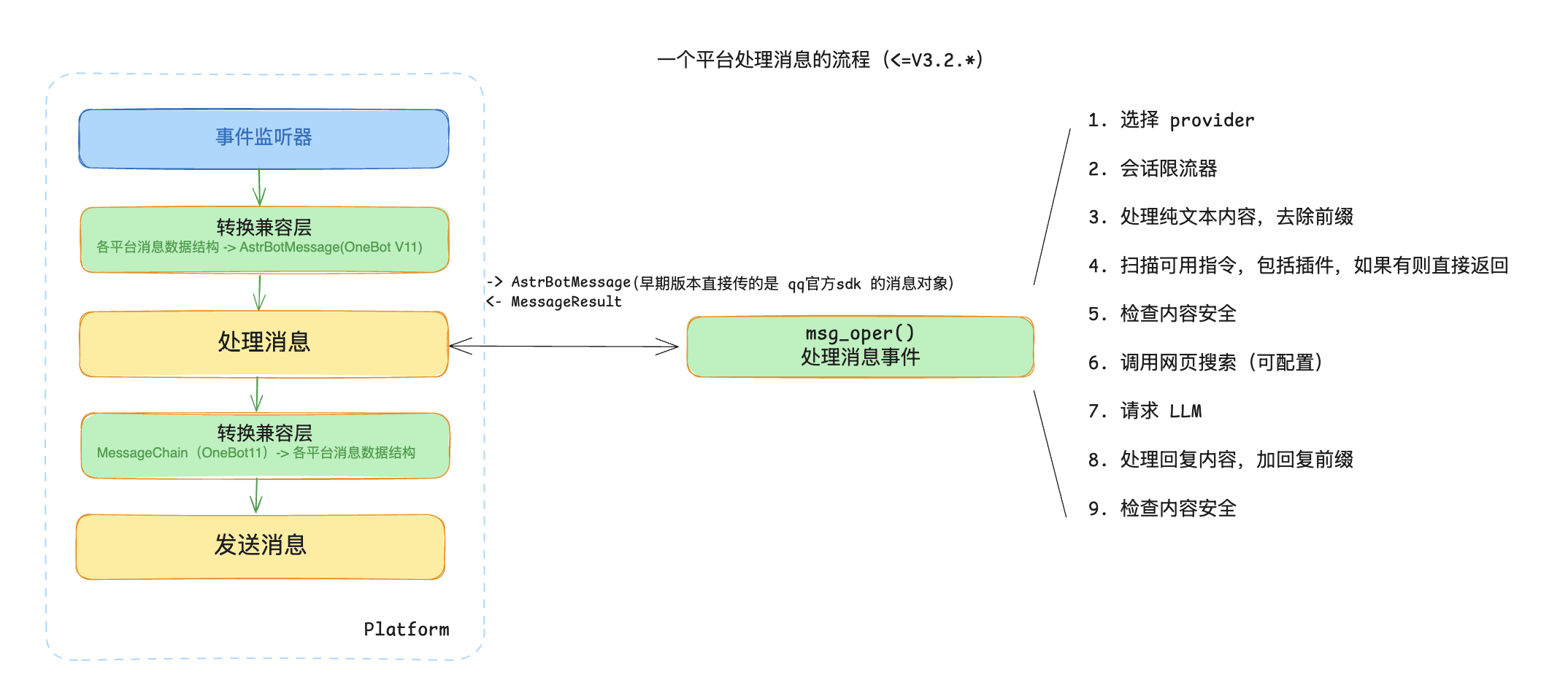
一开始的 AstrBot 几乎所有组件都写在 core.py 中,其中,在平台接收到消息之后,会调用 msg_oper() 函数并传入 AstrBotMessage, session_id: str, role: str, platform: str。然后执行图中的处理过程,然后返回 MessageResult。并且所有的逻辑都完全暴露在这个函数中,可读性非常之差。
第二阶段——解耦的开始
首先,心头之恨是这冗长的 core.py,我尽可能解耦了这个文件中逻辑独立的功能为独立的模块,比如 MessageHandler, Updator, PlatformManager, PluginManager, CommandManager 等等。
初始化程序
core.py 中的初始化机器人相关的逻辑单独抽离成了 AstrBotBootStrap 类,它依次加载:
- 配置
- CommandManager
- PluginManager
- AstrBotUpdator
- InternalCommandHandler
- 持久化层
- Provider
- MessageHandler
- PlatformManager
- AstrBotDashboard(可视化面板)
- MetricUploader(指标上报)
- 插件
- Platform
然后用 asyncio.gather()将消息平台监听、Dashboard 后端服务器、指标上报、插件注册的长任务这些异步任务收集起来运行。
1 | tasks = [metrics_upload_task, dashboard_task, *platform_tasks, *self.context.ext_tasks] |
消息处理

每个消息平台类在实例化的时候都会传入一个 message_handler 实例对象(MessageHandler 类),当消息平台接收到消息时需要主动调用这个对象中的 handle()方法来获取 AstrBot 处理该消息的结果。handle() 方法接受一个 AstrMessageEvent 对象,对象中包含了 AstrBotMessage 消息结构等内容。该方法会执行一系列消息处理流程,最终返回消息处理结果。本质是之前的 core.py中的 msg_oper()函数。
其实如果只从这个消息处理部分来说,似乎并没有太大的变化。但是由于已经把其他组件(限流器等)解耦,每个组件依照配置文件各司其职,于是更加灵活,代码可读性也高了不少。
但是随着插件功能的不断完善,社区群中一位开发者在尝试将 vchat 适配器(微信)以插件的形式接入 AstrBot 时遇到了一些问题,比如不清楚 message_handler 到底该怎么用。这是因为我将 message_handler 放在了插件的 Context 中,而由于依赖循环引用问题,导致没有写 type hint,最终难以找到这个实例的使用方法,非常不优雅,并且这让 MessageHandler 直接和 Platform 直接耦合在一起,增加了 Platform 的职责。
并且,由于频繁的更新没来得及仔细思考和某些反范式的消息平台(如 QQ 官方机器人SDK),导致我对 Platform 这个类的接口定义和职责较为混乱,比如 send_msg() 接口的第一个参数是要发送的消息链,type_hint 写的是 MessageResult,然而有时可能会直接传入一个字符串。同样是send_msg(),在当前的设计中需要额外处理文转图的情况,缺乏统一的处理机制,最终每个平台适配器都会实现这个逻辑,代码复用性降低。
总结一下,无非就是在扩展消息平台这一层面上,开发者要关注的内容过多,AstrBot 开放的接口对开发者透明,且结构混乱,最终会导致开发者写出耦合度高的代码,适配意愿度下降 。
这里的透明指的是黑盒
第三阶段——事件总线、事件驱动和流水线模型
为了解决上述问题,我采用了事件总线模型。
事件总线是一种用于管理和分发事件的机制,通常来说它用于解耦组件之间的通信。它像一个中央“通道”,允许发送者(事件发布者)将事件发送到总线,而接收者(事件订阅者)从总线获取自己感兴趣的事件。
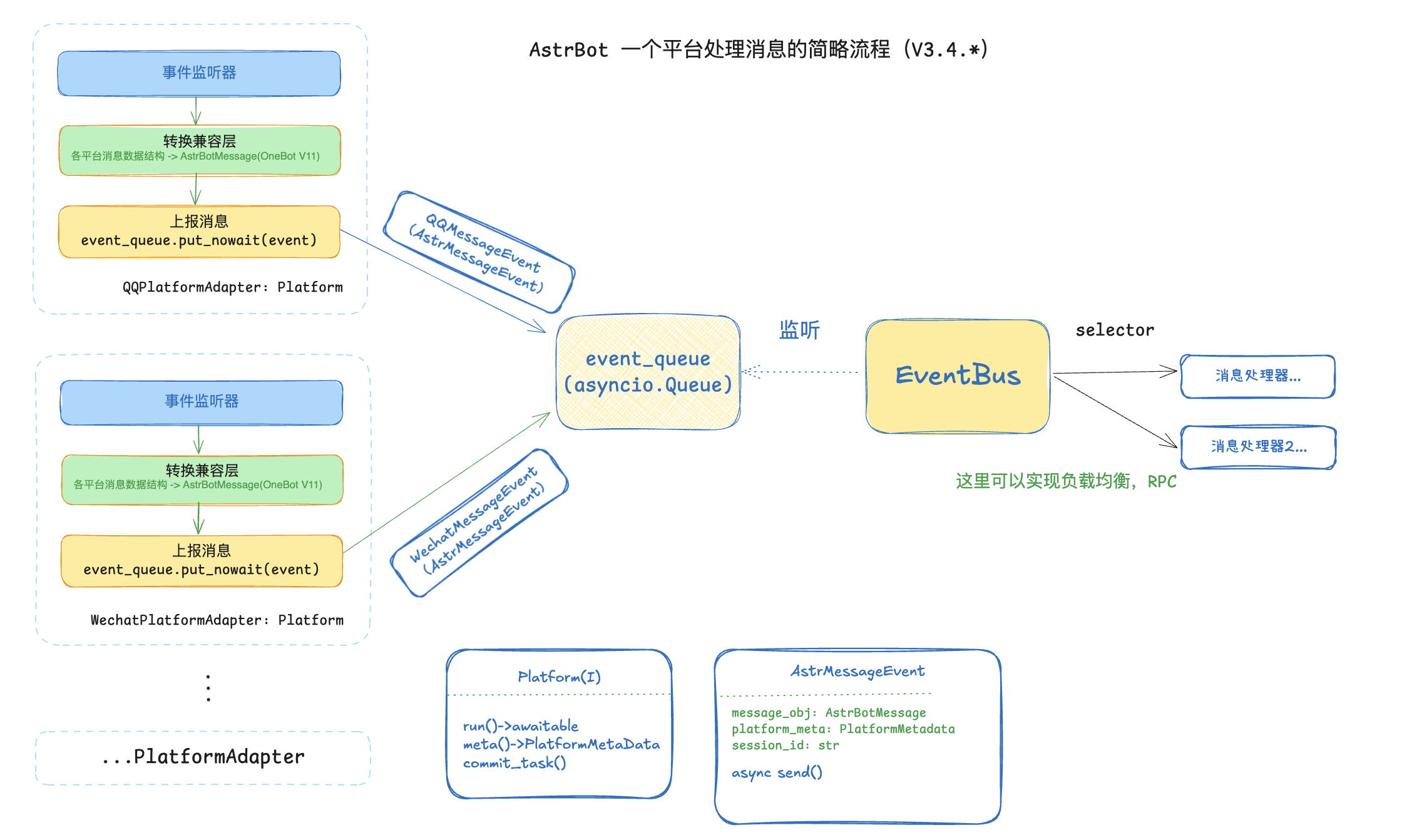
这种设计有很多好处。
对平台(发送者)来说,它减轻了平台的职责,有点像是 “平台只需要上报消息就行了,而接收者要考虑的东西就很多了” 这个逻辑。平台完全不需要关心处理消息的过程,也不需要持有消息处理器这一对象。只需要持有一个更加抽象的管道,然后在接收到信息,转换成统一的消息格式之后交付给管道即可。由于目前为止 AstrBot 内部已经近乎实现全异步化,因此,在这里我使用了 asyncio 的 Queue 来作为连接总线和消息平台的管道。
对消息处理器(接收者)来说,由于平台将处理消息的职责交给了接收者,那么可以采取更加粒度化的管控,比如对某个平台限流,负载均衡等等。
了解 Queue 的读者可能会问,单靠 Queue 实现全双工通信会比较复杂,如何解决发送消息的逻辑呢?确实,在之前的设计中,我们调用 message_handler.handle() 可以直接获得到结果,但是这里我们仅是使用 Queue 上报消息。难道再用一个 Queue 接收消息?其实这样也行,现在 AstrBot 的 WebChat 就是这样实现的。但是我使用了一个更加稳妥的办法:设置一个 AstrMessageEvent 类,每个平台适配器都被要求实现这个类和这个类的 send() 接口。通常来说,会使用依赖注入这个手段,将平台的回复消息的回调函数实例传给其派生的 AstrMessageEvent 类,然后把这个类对象传给 Queue。这样消息处理在回复消息的时候只需要调用 send() 即可,并且其参数只有消息链对象,非常的简洁。
这样还没完。在之前的消息处理器中,将所有处理消息的功能放在一起,比如限流器、安全检查、指令扫描。这对功能扩展来说非常不友好。在设计 astrbot_plugin_atri 这个插件的时候,我就开始发现其实这个处理消息的过程更像一个流水线(Pipeline),各种功能能够被归类到不同的流水线的阶段(Stage)中。于是,我将这整个消息处理的部分设计为了一个 Pipeline。
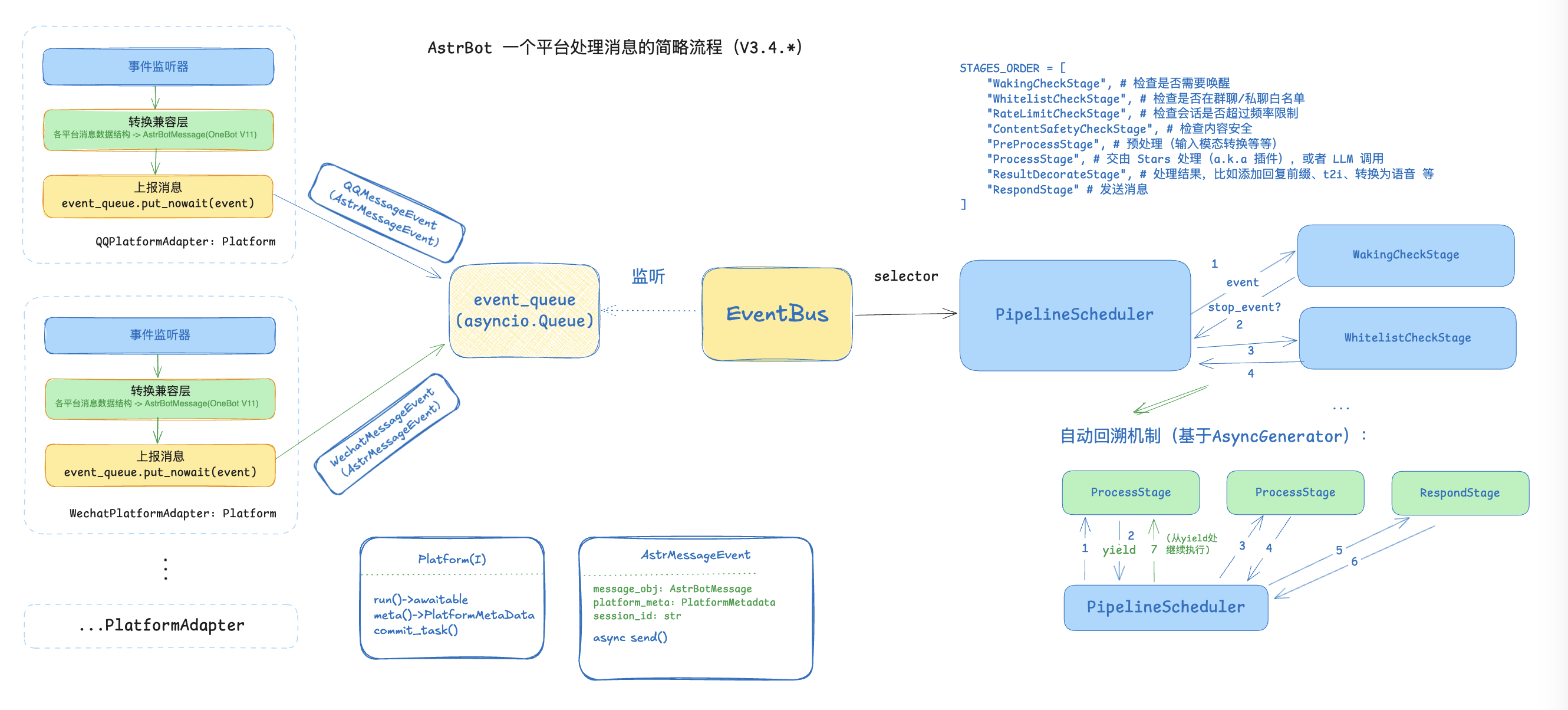
事件总线持有一个流水线调度器(PipelineScheduler),调度器将根据预先设置好的 STAGES_ORDER 按顺序执行流水线阶段的 process(event)方法,这个在多个阶段中顺序执行的过程被称为 事件传播(Event Propagation)。得益于 Python 生成器的特性,当某个阶段 yield 之后,调度器将会记录该点位,然后继续往下执行后续流水线再返回到该阶段中。
这样的设计将之前的 MessageHandler 又进行了一次彻底的解耦,在灵活度提升的情况下也提高了代码的可读性。并且考虑到插件扩展功能时可能会在不同的 Stage 做扩展,比如考虑某个 RAG 插件,如果它使用默认的这个消息处理流程,那么它就需要在请求 LLM 前召回相关文本并修改请求 LLM 的上下文。再比如某个语音转文字插件需要在 Preprocess 阶段将语音消息段转换为文本消息段。
主动消息的设计
一个消息平台应当支持被动消息(回复)和主动消息的发送。
被动消息指的是消息事件在传播时给消息平台发送的信息,使用 send() 方法即可实现这一目的。被动消息回复的实现不复杂,因为 AstrMessageEvent 持有 AstrBotMessage对象,其包含了发送人的所有信息,在实现 send() 回调的时候直接根据这个对象中发送人信息发送即可。
而主动消息需要是没有 AstrMessageEvent的,换言之,插件或者某个长任务可以随时给消息平台发送消息。这该如何解决呢?
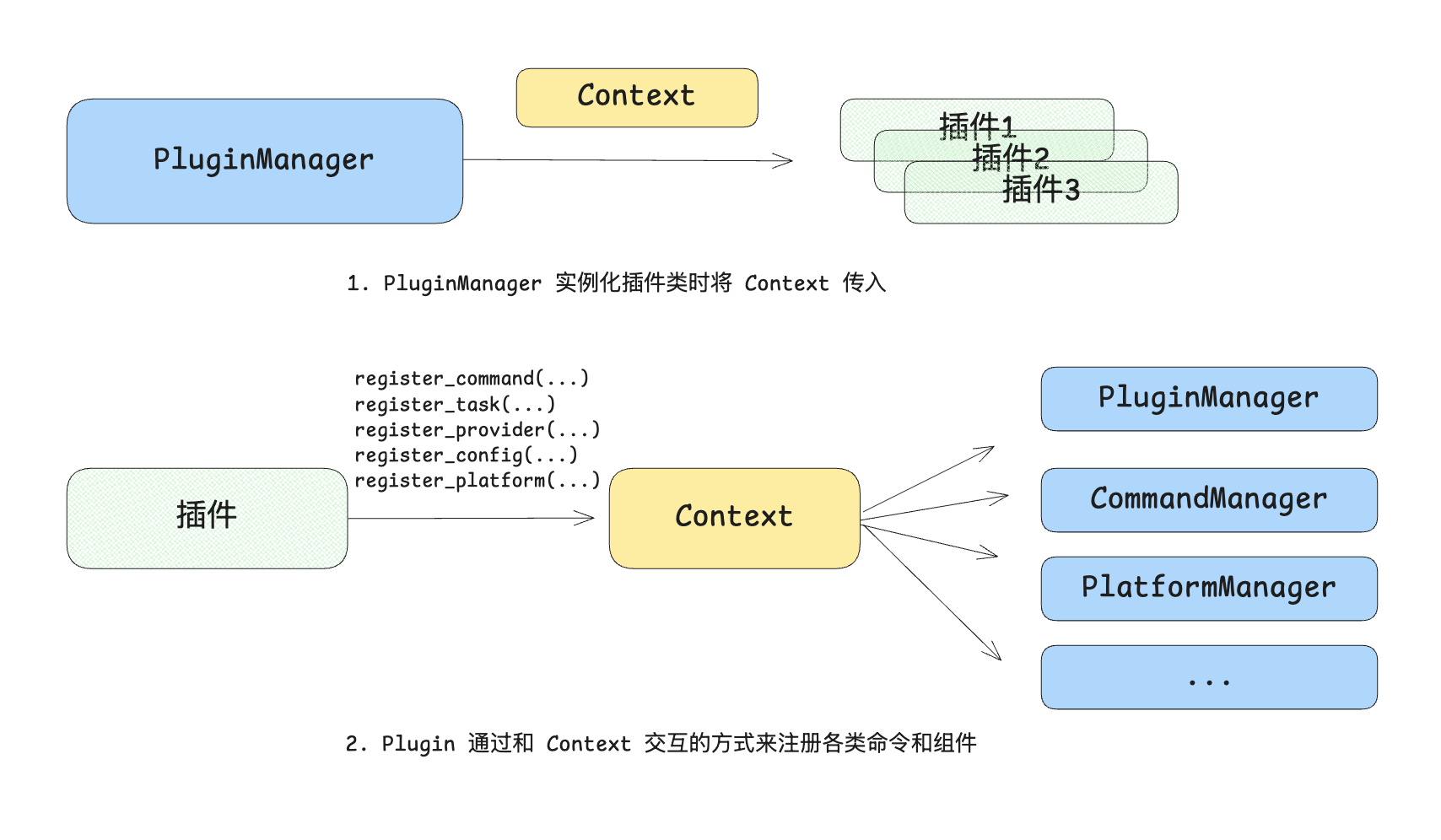
插件在初始化的时候会被传入一个 Context 对象,这个 Context 持有 PlatformManager,这样只需在 Context 中设计好相关发送接口即可。
那如何确定发送人的信息呢?每个平台都是异构的,所需的信息不尽相同,不同的消息类型(群聊、私聊)所需的信息也不同,并且机器人将消息发给哪个消息平台也很难确定。
在早期的设计中,Context 中的发送接口商定好发送人的信息统一用一个 dict 来传递,并且在文档中写明了哪个消息平台的发送人信息的格式是什么。
但是这样还是太复杂和不稳定。我们需要设计一个开发者无感的发送方式。
于是我设计了一个名为 unique_msg_origin 的消息结构,其实他就是一个字符串,包含了平台类型、消息类型(群聊还是私聊)、发送源的 session_id,并用 : 来分隔,如 aiocqhttp:FriendMessage:905617992。这三个信息已经能够满足所有的消息平台的主动信息发送的需求(因为 session_id 也是消息平台适配器自己指定的,它们可以在这上面存入更多信息)。
于是只需要保存好unique_msg_origin(由于是字符串格式的,也很方便持久化),调用 Context 中的接口传入unique_msg_origin 即可。