部署的注意事项
网上已经有很多部署教程了,这里不做详细阐述
- 注意如果要自己安装,jdk要用oracle的rpm包。
- 关闭高水位只读限制:
1 | curl -XPUT -H "Content-Type: application/json" http://192.168.111.300:8060/_all/_settings -d '{"index.blocks.read_only_allow_delete": null}' |
原理
存储
ElasticSearch 基于 Apache Lucene 倒排索引实现,比关系型数据库如MySQL过滤更快。
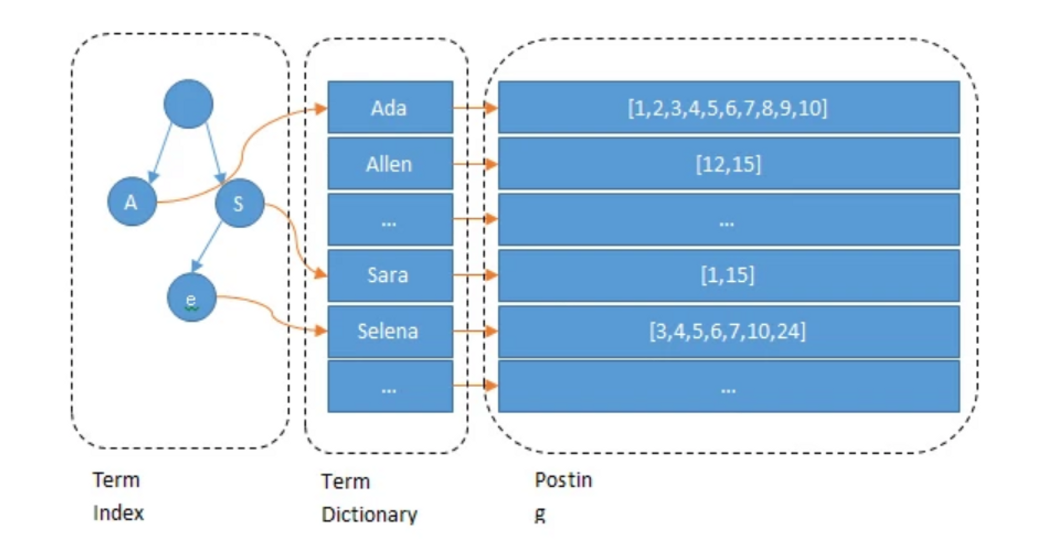
MySQL通过将 Term Dictionary 以 B-Tree/B+Tree 的形式存到磁盘中。将多个值作为一个 tuple 通过连续区间存放。 能减少寻道次数。
Lucene 在 Term Dictionary 的基础上加了一层索引——Term Index(在内存中,并且可以使用一些压缩技术, 如 FST , 来减少内存占用),通过它可以快速找到 Term Dictionary 的块的位置之后再去磁盘上找term. 这样就可以快速根据 term 找到 Posting list, 从而快速找到数据.
压缩技巧
存 Term Index 的压缩方案: FST
存 PostingList 的压缩方案: 增量编码存储和Roaring BitMaps。
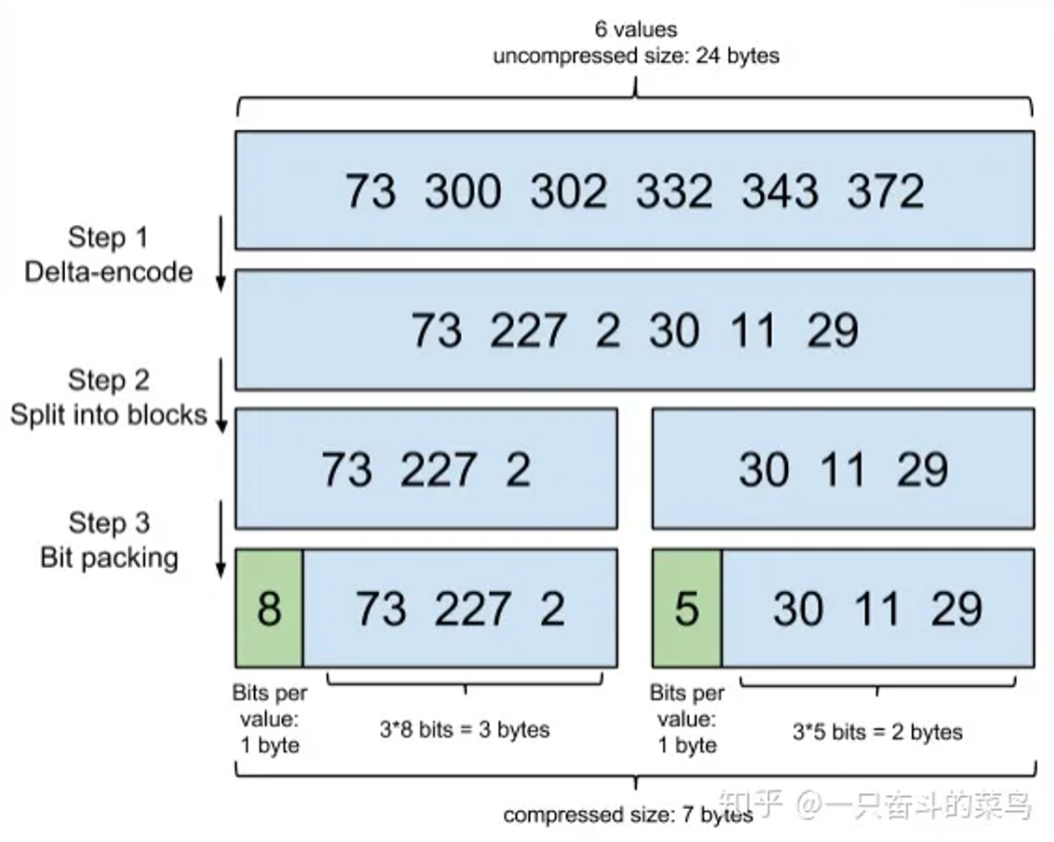
增量编码存储
通过增量,将原来的大数变成小数仅存储增量值,再精打细算按 Bit 排好队,最后通过字节存储。
Roaring BitMaps
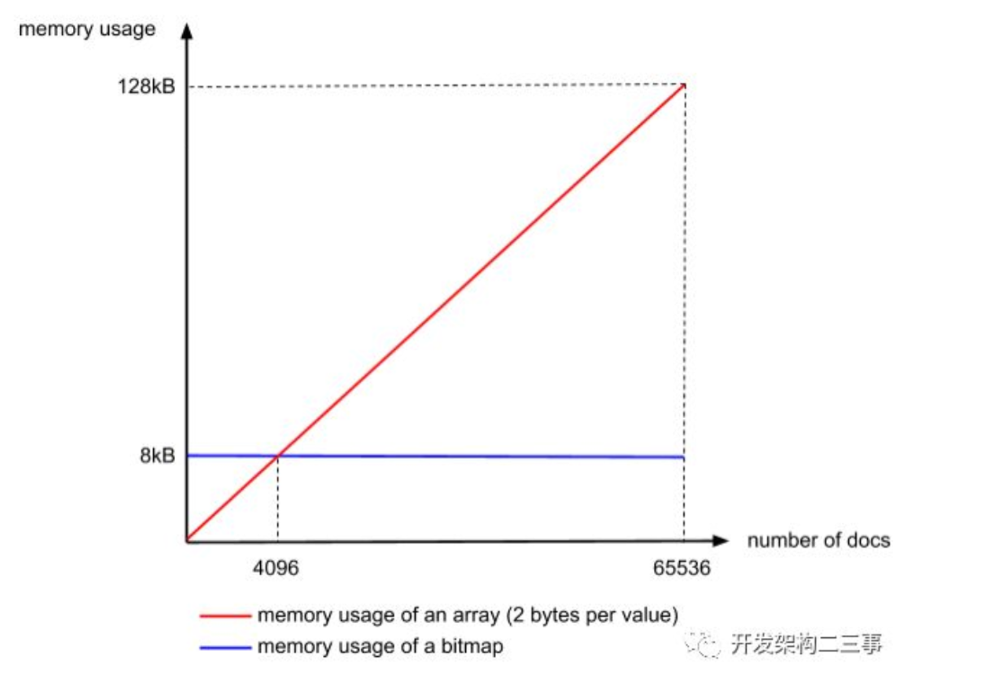
如 [1,3,4,7,10] 这个 Posting BitMap 对应的Bitmap 就是:[1,0,1,1,0,0,1,0,0,1]。BitMap第 0 对应 PostingList 的1。
可想而知,这会指数级地增加BitMap的大小. 因此 ES 对其做了限制:Posting List 以 65536 为界限分割。这样如果仅用 BitMap,那最多只有 65536bit,即 8KiB。如果当前块仅有少于 4096 个值, 那么直接用 Short[] 来存而不用 BitMap。(这也说明了为什么是65536)
联合索引
- 获得多个索引的 BitMap,然后按位与
- 利用跳表。
写入
- 路由选择协议通过设置的 routing 或者hash 确定写入到哪一个 Shard。(一个 Shard 包含多个节点,Primary 和 Replica 节点), 然后找到 Primary 节点.
- 写入数据到该节点: 写入到其内存缓冲区中,再写入 Translog 的缓冲区中, Translog 实时刷入磁盘。 一定时间 (1s) 后,将缓存的 doc 形成一个新的 Segment,并打开该 Segment 使其可以被搜索(Refresh),并生成一个新的Commit point 来记录当前可用的Segment。一定时间间隔后(或者translog足够大时),执行 Commit, 将缓存的所有 Segment 写入磁盘(Flush).
*Segment 已经写入不可更新和删除,可以打标记。
*ES会定期将小的 Segment 和使用量小的 Segment 合并, 合并时如果发现其 doc 在 .del中有记录就删掉,并且 .del 也删掉.
集群
Node
支持水平扩容,PB 级别的存储量.
节点加入后默认是 Data Node, Ingest Node, Master Eligible Node, Coordinating Node。
Ingest Node 用来对文档在编制成索引之前进行预处理, 因此 CPU 需求较大.
Coordinating Node 处理/分发路由请求, 并对请求结果进行汇总.
最佳实践: 为一个集群分配多个 Master Node, 每个 Master Node 只承担一个角色。
Master Node: 创建,删除索引。决定分片被分配到那个节点。维护并更新 Cluster State
发现机制
- 新增节点时要用到
- Master 节点故障时,要通过选举找到新的 Master.
节点间通信是通过基于 AIO 的 TCP 实现的Transport 模块实现的.
一个节点启动之后通过 Seed Hosts Providers 得到 Seed addresses,然后在这之中去一个一个尝试连接, 直到找到足够数量的 Master Eligible Node 可以参与选举 Master Node 为止。如果没有 Node,则会每隔 1s 重复搜索。
选主
在所有的 Quorums 中选择一个 Node 作为 Master Node。Quorums 是集群中所有 Master Eligible Node 的一个子集
采用抢占式选举:如果 Master 挂掉之后, Master Eligible 会随机时间进行选举, 第一个选举的会成为新的 Master。 当多个 Master Eligible 同时选举时, 选举失败并重试.
分片 Shard 和故障转移
Shard 是物理空间概念,索引中的数据都分布在分片上,一个分片就是运行的一个 Lucene 的实例。 主分片支持读写,副分片只读,主分片写入时要同步给副分片。相同的索引,主分片和副分片不能存在同一个 Data Node。
主节点维护:Index 的信息、Shard 上的数据信息
数据如何均匀分配到不同分片? 使用 Hash。
1 | shard = hash(_routing) % number_of_primary_shards |
_routing 默认是文档的 Id。可以自己指定:
1 | //插入数据时,通过 routing 参数指定 _routing |
流程:
1 | 1. 更新文档的请求先发送到某一个 Coordinating Node 上 |
企业内部 ES 流量梳理
HA → LVS(负载均衡) → ES集群 → ES主节点→ES数据节点(热、冷)
ES 分布式一致性协议
6 → bully(zen协议)
7以后 → raft 协议
优化
ES
- mapping优化
- scroll
- filter
JVM
- 指针压缩
- GC线程数调整
- GC内存空间调整, 各个代际的调整
- heap外可用空间调整