引言
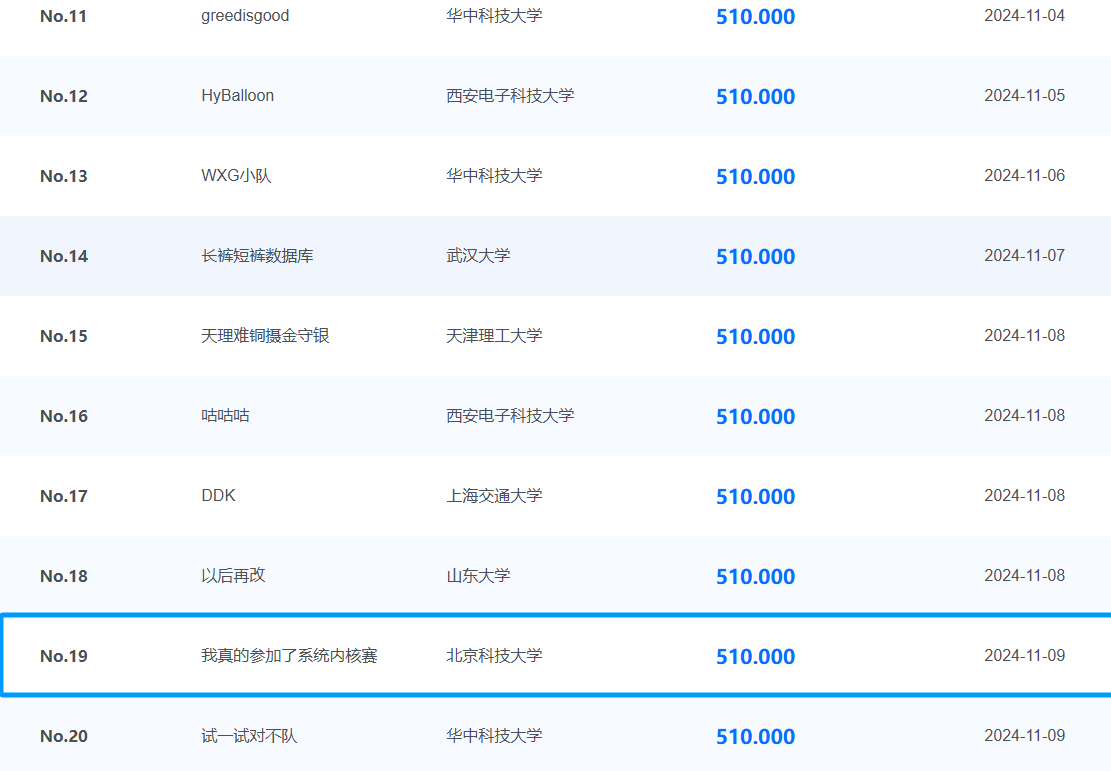
在十月中旬,我们参加了由 OceanBase 举办的为期半个多月的数据库内核实现赛,我们花了大量的时间实现赛题要求——日均 8 小时。不得不说,这是一个非常能让人 “上瘾” 的比赛 orz。有时候,在熟悉代码、debug 的时候,不知不觉 2 个小时就过去了。在和队友(@Nelson, @z2z63)的努力下,我们最终在 2024.11.09 初赛拿了满分,位列全国第 19/1212 名,北京市第 2 名,全校第 1 名。
这篇文章是我在比赛中的开发记录,由于是边思考边写出来的,未经过后期处理,可能有一些地方表述不清晰。迫于时间和个人对 C++ 的掌握程度有限,有些实现方法会比较抽象,请见谅。
队友的请参阅:
- Nelson:OceanBase 2024
- z2z63:OceanBase 数据库大赛初赛结束之后
数据库的基本思想
一个数据库可以是这样:
1 | my_db = open("mydb.txt", "a", encoding="utf-8") |
事实上,我刚开始了解数据库时也有这个想法。不过,数据库除了文本类型的数据,还支持很多数据类型,如 int、date、boolean、vector 等。如果全基于字符串存在文件里,势必造成很大的转换开销。此外,还有锁、更新数据、事务等等机制,如果仅靠一个简单的 txt 格式的文件,虽然最终可以实现,但终究不够优雅,且性能 = 💩。
在 miniob 中,SQL 的执行过程大致如下:
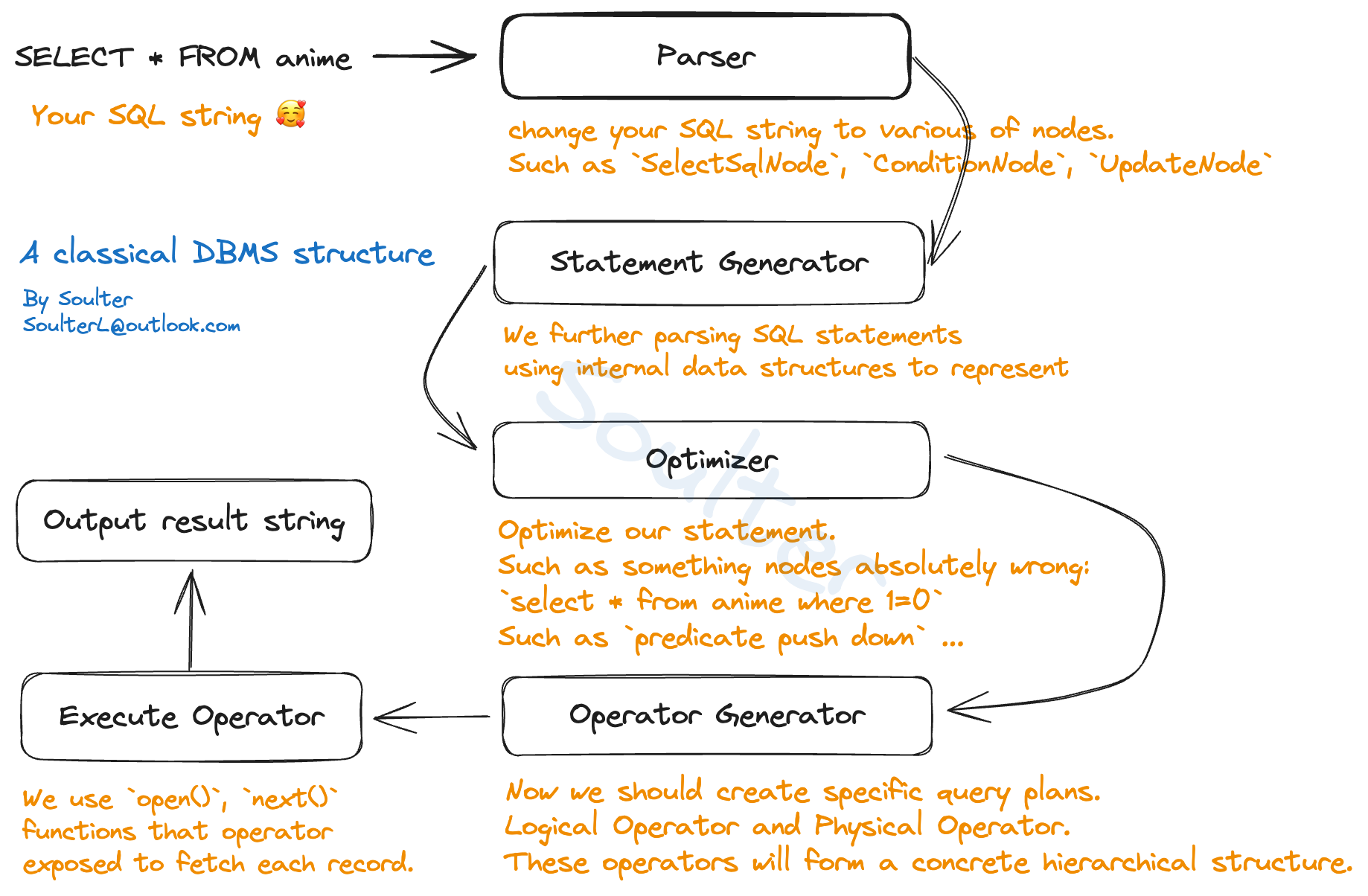
和所有编程语言一样,当我们发送一个 SQL 请求,程序首先会进行语法解析阶段,生成抽象语法树(AST)。这一步用到了 flex 和 bison,前者用于词法分析,将 SQL 语句分割成 Token,后者用于语法分析,将 Token 组合成 AST。在 miniob 中,解析好的数据放在 ParsedSqlNode 中。
例如,我们请求: select * from tb where id=1;,解析后 node 如下:
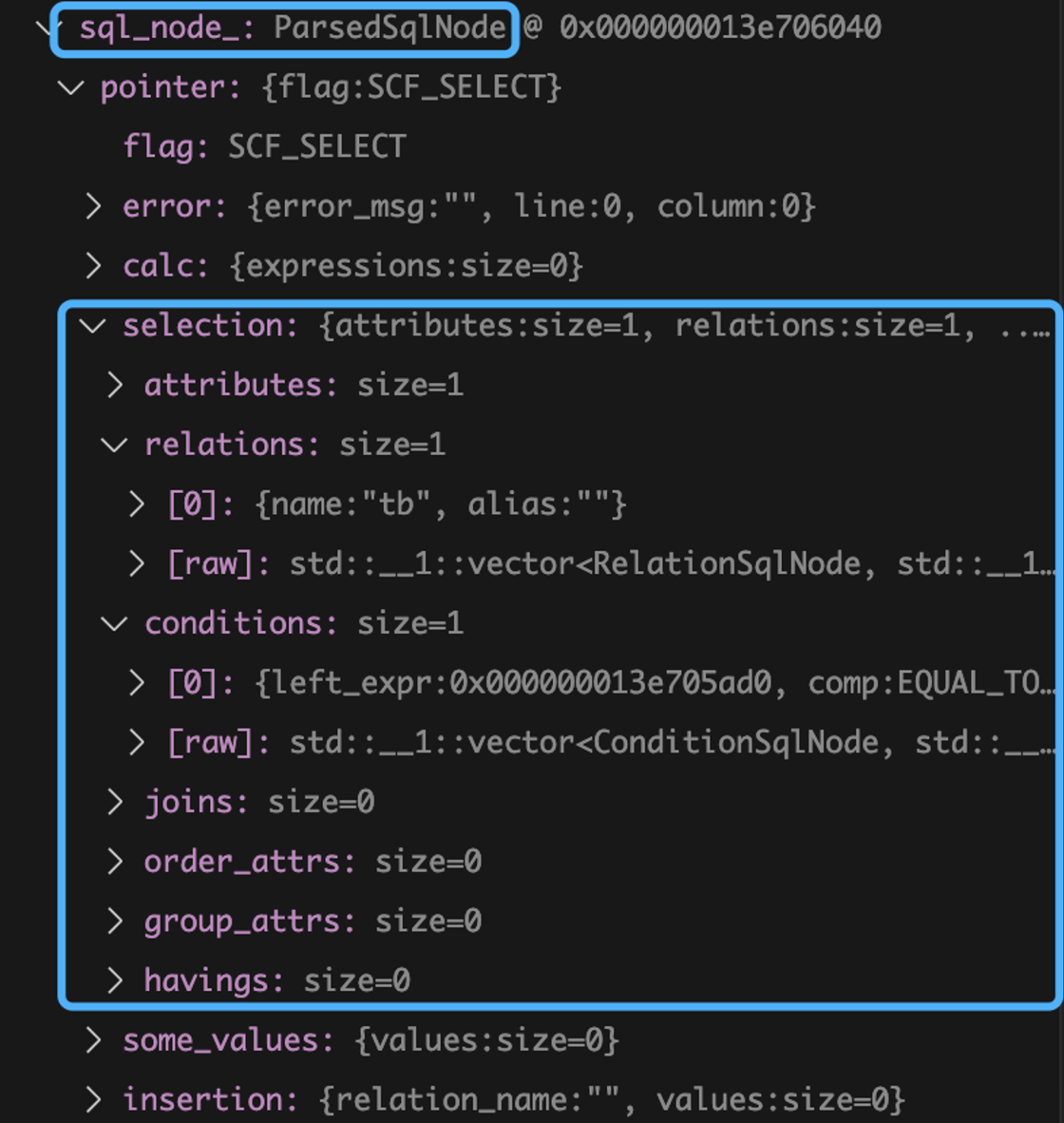
解析好数据后,只是 “语法上” 合法,逻辑上是否合法还需要进一步检查,这一步叫做语义分析。miniob 会对 ParsedSQlNode 进行进一步分析,比如检查字段、检查表是否存在、绑定表和表达式、隐式类型转换等等。这一步的结果是生成一个 Statement。
语义上也没问题之后,我们就进入了优化阶段。优化的目的是尽可能地减少查询的时间和资源消耗。在 miniob 中,优化过程中先生成了逻辑计划,可以把它想象成一个逻辑算子(Logical Operator)构成的树——它表示了整个查询的逻辑结构。每种查询模式(如投影、连接、过滤、排序、索引)都有一个算子,然后组合成逻辑算子树。生成算子树之后,miniob 会对逻辑算子进行 rewrite,在这一过程中,会将可能的 where 条件下推到底层并对一些结果绝对正确/错误的条件做相关处理,以减少数据在算子中的传递。
rewrite 阶段完成之后,就开始生成真正的查询计划,也叫物理查询计划。物理计划会根据 rewrite 结果的逻辑计划来生成。最终的执行阶段就是按照物理查询计划执行查询,得到结果。
考虑一个最简单的 Select 请求:select * from tb where id=1。最终生成的物理算子的一种可能的结构如下:
1 | (顶层)ProjectPhyOperator -> PredicatePhyOperator -> TableScanPhyOperator(底层) |
每一个算子所做的工作都是不同的,比如上面的示例中,最底层的表线性扫描算子将调用某个 Table 实例中的 FilePageScanner 来扫描表中的所有记录,得到 Record,形成 Tuple,然后中间的过滤算子会根据 where 条件来决定是否选取这个 Tuple,最顶层的投影算子根据查询字段来筛选出 Tuple 中的 Cell(也就是筛选出要显示的列)。最终前端从 ProjectPhyOperator 中拿到选择好的结果并输出。如下图所示:
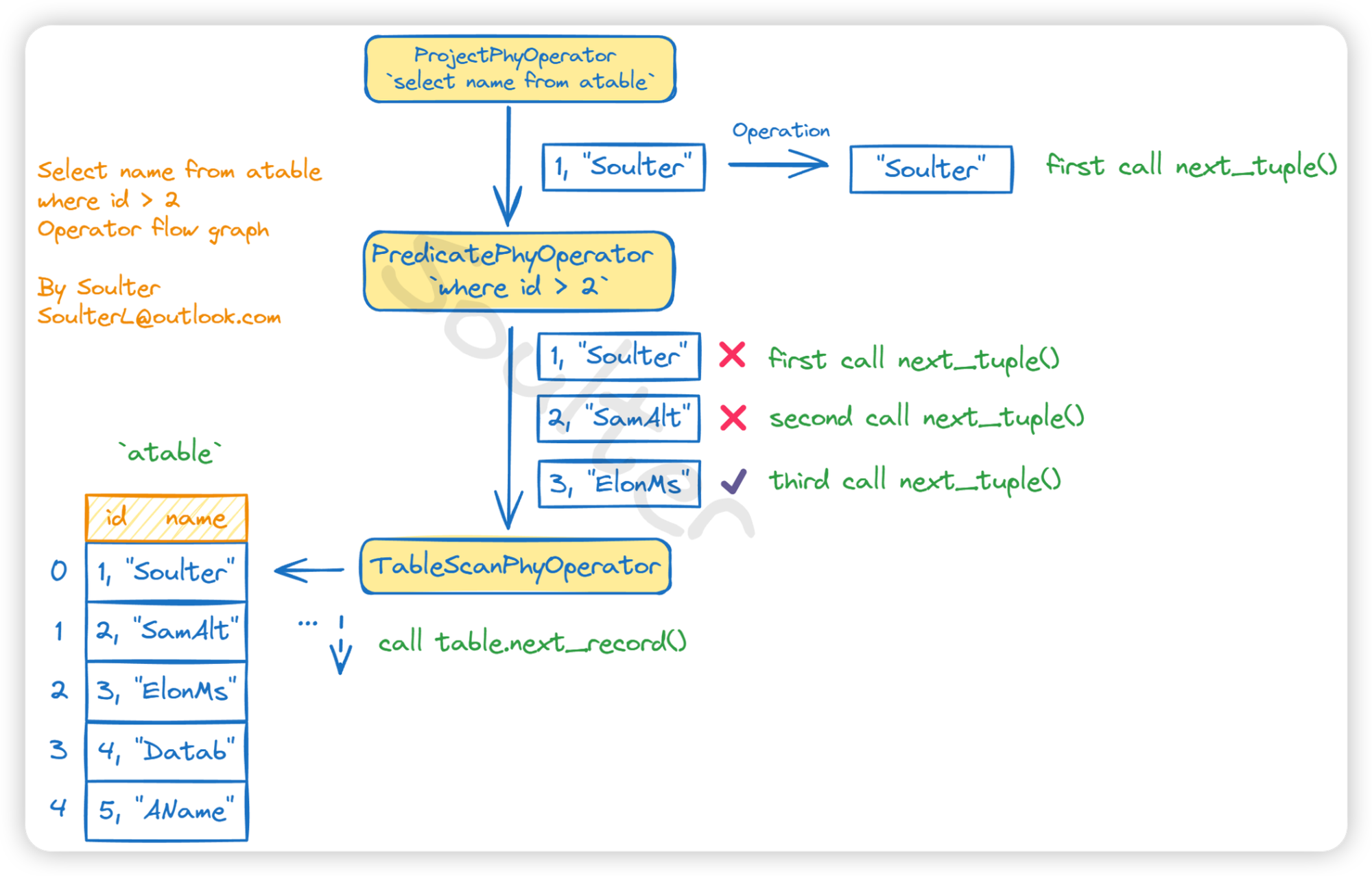
如你所见,经典数据库系统中的算子执行过程就像齿轮转动,采用分而治之、层级化思想,将数据一步步处理,最终将结果呈现给用户。
实现记录
Update
和 Delete 操作类似,当我们写好语法解析部分和 Statement 之后,单独新建一个 Update 的逻辑算子和物理算子,将要更新的表、字段(FieldMeta)、值(Value) 在算子生成阶段传递给算子。
- FieldMeta 即字段元数据,存储了一个表中某个字段的元数据,如类型、偏移量、长度等。
- Value 即一个确切的值,存储了 Value 类型、具体的值等。
物理算子的实现上,将底层的 RowRecord 拿到之后,通过其中的 RID 即可在 Table 中找到对应的 Record 记录。然后再通过 FieldMeta 找到字段在 Record 中的偏移量和长度,最后更新为 Value 中的数据即可。如果实现了索引,还需要更新索引,这里我直接先把索引中记录对应的 node 删除,然后重新插入。
Record 类中记录了
RID和Table,前者记录了这个 Record 的page_num和slot_num。一个File含有多个Page,一个Page含有多个Record。Page 的 Header 中存放了一个 BitMap 用来描述 Page 的空间使用情况,一个 Record 一个 bit。可以通过slot_num来检查这个Record是否曾被删除。
还应当注意一些语义检测:
- 检查 Table 是否存在;
- 检查 SET 部分指定的字段名是否存在于指定的 Table 中;
- 类型判断和隐式类型转换。
- …
隐式类型转换
在 MySQL 中,是支持针对字段和值的隐式类型转换的。例如
- int cast to float (或者相反)
- chars cast to int (或者相反)
- chars cast to float (或者相反)
转换过程的核心代码如下:
1 | // 字段类型检查 |
对于 chars 类型转 int 或 float 类型,在 MYSQL 中有一个额外的智能的处理逻辑:
- 非数字字符不包括小数点。
- 当 char* 中遇到第一个非数字字符时,直接返回。若第一个就是非数字字符,那么返回 0。
- 当遇到数字字符时,和前面的数字字符组装形成新的值。
- 当遇到小数点时,开始加上小数部分。
Vector(向量类型)
这题主要实现向量数据库中的向量类型:
- 支持创建包含向量类型的表。
- 支持插入向量类型的记录。
- 支持向量类型的算术运算(加法(+),减法(-),乘法(*),比较运算)。
在此之上,实现一些简单的距离表达式计算:
l2_distance, cosine_distance, inner_product.
加类型很好解决,首先在 yacc 和 lex 文件上引入新的类型:VECTOR_T
1 | // lex |
这里正则表达式用于匹配 '[1,2,3]', "[1,2,3]", [1,2,3] 这三种写法,并忽略了元素之间可能出现的空格,比如[ 1, 2, 3 ]。
1 | insert_stmt: /*insert 语句的语法解析树*/ |
value.cpp 文件,from_vector 将向量字符串传入,解析成 Value 类型。在这里,我使用了 std::vector 来暂时存储向量的值。
1 | // 从向量字符串创建 Value |
考虑到从顶层的视角来看,向量类型的长度就是向量的维度,因此这里 length_ 的值就是向量的维度而不是 sizeof(float)*向量维度。但这也意味着需要在底层做一些额外的处理,把长度转回 sizeof(float)*向量维度。
由于用户存入的向量的长度不固定,这里我将 nan 作为结束的标志(在存入长度<创建时设置的最大长度 的情况下)。
1 | const char *Value::data() const |
两个向量之间以字典序的方式比较大小:
1 | int VectorType::compare(const Value &left, const Value &right) const |
实现三个距离函数:
主要是添加了一个 VectorDistanceExpr 类型(继承自 Expression)。
同样需要现在 yacc 和 lex 文件中补充新的 Token 类型,然后在解析语法树时创建 VectorDistanceExpr ,不再赘述。
在 VetorDistanceExpr 的 get_value 方法中,添加相关的计算逻辑。
1 | RC VectorDistanceExpr::get_value(const Tuple &tuple, Value &value) const { |
Join
miniob 已经实现了基本的多表联查功能,主要使用了 Nested-Loop Join 算子。我们的工作主要是实现 INNER JOIN 语法解析即可。
首先在 yacc 文件下,补充 Join 相关的语法。唯一需要注意的是由于语法树是递归顺序解析的,因此需要将解析得到的 join_list reverse 一下。
在 parse_defs.cpp 文件下加一个 JoinSqlNode:
1 | struct JoinSqlNode |
然后理论上就已经实现了。
结果发现一直不过测,开始还以为是 Nested-Loop Join 太慢了,花了一些时间重新实现了 Block Nested-Loop Join,结果仍然不过。最后发现是在 Optimize 阶段的 Predicates 算子下推步骤时,原框架在使用迭代器遍历 vector 时,删除了元素但没有更新迭代器,导致了错误。。。。不得不吐槽 miniob 的代码质量。。。
以及最后在实现与 OR 有关的的下推步骤时,发现判断是否要将
ComparisonExpr下推的逻辑都有问题。
Block Nested-Loop Join
既然提到了 BNL,那就简单介绍一下 BNL 的原理。
Block Nested-Loop Join(BNL) 是 Nested-Loop Join(NLJ) 的一种优化,其思想是将左表(外部表)分块(缓冲),来减少对右表的访问次数。比如我们有两个表 A 和 B,A 有 1000 行,B 有 10000 行,我们可以将 A 分成 10 个块,每个块 100 行,然后对于每个块,我们只需要扫描 B 一次,而不是 NLJ 的 1000 次。
从原理上来说,实现起来很容易,加一个 vector 存储左表的记录(tuple)作为一个块,然后再做一些处理即可。实际上,在 miniob 中,tuple 在算子中是以指针的形式传递的,而不是复制。这就导致在下一次算子循环中,原来存的指针会指向新的 tuple,这就导致了错误。处理起来比较麻烦,所以最终也没有用上这个优化。
Simple Sub Query
需求分析
在简单子查询中,我们要需要在 WHERE 子句中支持 SELECT 语句,如下:
1 | SELECT * FROM tb WHERE tb.id IN (SELECT tb2.id FROM tb2); |
除此之外:
- 添加针对 IN、NOT IN、EXISTS、NOT EXISTS 的支持。
- 添加对常量值列表的支持。如
SELECT * FROM tb WHERE tb.id IN (1, 2, 3);
需要注意的是,子查询的一些特性:
- 子查询的结果集只能有一列
- 对于 IN、NOT IN、EXISTS、NOT EXISTS,子查询的结果集可以是任意行数,但是对于除此之外的情况,子查询的结果集只能有一行。(MYSQL ERROR 1242 (21000))
- 常量值列表仅会用在 IN、NOT IN、EXISTS、NOT EXISTS 中。
实现
考虑到子查询在 WHERE 中,我们就将其全部放在 Conditions 中处理。
1 | struct ConditionSqlNode { |
好在 Condition 的左右两边都被抽象成了 Expression,我们只需要在 Expression 类下加入一个新的类型 SubqueryExpr 即可。然后在 expression 的语法解析树中加一个 LBRACE select_stmt RBRACE 的语法规则,就能完成语法解析。
还有常量值列表,就更容易了,开一个 ValueListExpr 类型,然后存 std::vector<Value> values_; 即可。
对于 EXISTS、NOT EXISTS,由于它的查询 SQL 是这样的:SELECT * FROM tb WHERE EXISTS (SELECT * FROM tb2 WHERE tb.id = tb2.id); 它是没有 left expression 的!在这里,为了统一性,我单独创了一个 SpecialPlaceholderExpr 类型,用于表示没有 left 的情况,它没有实现任何方法。
那该如何“查”这个子查询呢?我在创建主表的 SelectStmt 的时候,对其 conditions 做了检测,如果监测到 SubqueryExpr,就对其下的 SelectSqlNodes 再创建一次 SelectStmt。这样就能递归地查找到所有的子查询并创建 stmt。
同样地,在逻辑查询计划和物理查询计划中,也提取出 SubqueryExpr 并创建对应的逻辑计划算子和物理计划算子。所有的子查询顶层算子都暂时存储在自身的 SubqueryExpr 中备用。
到了外表执行物理算子了,由于子查询在 Condition 中,最终外表的 ComparitorExpr::get_value() 方法中的 left 或者 right 可能是 SubqueryExpr。我们需要在这里判断子查询的情况。
一共有三种情况:
- left_ 是子查询 且 right_ 是子查询
- left_ 是子查询 或 right_ 是子查询
- left_ 是常量值列表 或 right_ 是常量值列表
- 其他情况
其他情况也就是 miniob 的默认处理方式。对于第一种情况,由于子查询仅能返回一行,我们额外需要注意在对 left/right 调用 get_value() 方法后,还要再调用一次,以保证其只返回一行,如果第二次 get_value() 成功了,就直接报错。
第二和第三种情况稍微复杂一些,由于 IN、NOT IN、EXISTS、NOT EXISTS 可能需要遍历整个子查询的结果集,我们需要开一个循环来对 left/right 调用 get_value() 方法。并在这个循环中写好一些 fast-break 的逻辑。比如:
- 对于 IN,如果在子查询中找到了第一个匹配的,就直接返回 true/false。
- 对于 EXISTS,如果在子查询中找到了一个匹配的,就直接返回 true/false。
尤其注意对其他比较操作符的处理,比如 =, !=, >, < 等等,子查询都只能返回一行。
尤其注意对 SpecialPlaceholderExpr 的处理,如果 left 是这个表达式类型,那么不需要对其调用 get_value() 方法。
在 SubqueryExpr 的 get_value() 方法中,如果检测到物理算子还没有 open,就先 open,然后调用 get_next() 方法得到 value,就大功告成了。
总体上简单子查询的大体逻辑就是这样,很多的细节限于篇幅都没有展开。
我很想说的一点是为了实现子查询的异常处理,比如子查询不能返回多行,我们需要修改一下前端部分。在 plain_communicator.cpp 文件下,记录了将表头、tuple 打印到输出流的逻辑。由于针对子查询不能返回多行的检测是在执行物理算子时动态检查的,也就是说,在获取整个查询的第一行结果时,检测到子查询输出了第二行时,表头已经写入输出流了。所以,我们应该将写入表头的操作放在“成功获取到整个查询的第一行”之后。
此外还有一点,由于这里子查询的实现重复调用了物理算子的 open 和 close,因此一定要注意保证在重复关闭/打开算子具有幂等性——即多次调用不会产生副作用。说人话就是记得在 close 时清理算子使用的资源。我在写子查询的时候就遇到了这个问题,由于 OrderBy 关闭算子时没有将 tuple_idx_ (用于标记当前 emit 到第几个 tuple)置 0、tuple_ 置空,导致了重复调用物理算子时出现得到的结果不一样:
1 | tb: |
查询语句是:
1 | SELECT * FROM tb WHERE tb.id > (SELECT tb2.id FROM tb2); |
正确情况下会返回一行,但是由于上述问题在将 tb.id=1 与 tb2 比较时,跳过了 tb2.id=0,导致没有返回结果。
Complicated Sub Query
需求分析
复杂子查询和简单子查询类似,但是多了子表之间的嵌套。比如:
1 | SELECT * FROM tb WHERE tb.id = (SELECT tb2.id FROM tb2 WHERE tb2.id IN (SELECT tb3.id FROM tb3)); |
这其实还好,由于简单子查询的设计,我们已经可以这样嵌套了。
并且,子表中还能使用外表的字段,比如:
1 | SELECT * FROM tb WHERE tb.id = (SELECT tb2.id FROM tb2 WHERE tb2.id = tb.id); |
诶,这就有点意思了。本质上,只是需要让子表的物理算子中持有外表的当前的 tuple 即可。
实现
在算子执行时,PredicatorPhysicalOperator 会在取出 tuple 后会执行 ConjunctionExpr 表达式,这个表达式又会执行若干个 ComparitorExpr 表达式。而在 Expression::get_value() 方法中,是有传递下来当前 tuple 的。我们可以借此在 open 子表物理算子的时候传给它。
总体上,算子的执行顺序主要有以下两种(在实现了 order-by 和 group-by 之后):
- 普通: proj -> orderby -> predicate -> …expr
- 聚合: proj -> orderby -> groupby -> predicate -> …expr
我们将 外表tuple 传给 proj,然后逐层传递给到 predicate,在 predicate 中使用 JoinedTuple 来存储外表的 tuple 即可!这样,predicate 在执行 expr(如comparitorexpr)的时候,这个 expr 就能持有外表的 tuple 了。妙不可言!
为什么要在 open 的时候就传而不是 next?因为某些算子如 order-by 在 open 的时候就会把其子算子 next 完,以排序/分组等。
此外,这题需要预先实现 alias。实际上,我将这题和 alias 放在一起写了。
Alias
需求分析
这一题需要实现别名,包括表、列的别名。比如:
1 | SELECT tb.id AS num, tb.name AS name FROM tb AS t WHERE t.num = 1; |
并且,需要支持在子查询中使用别名,比如:
1 | SELECT t.id, t.name FROM tb AS t WHERE t.id IN (SELECT t2.id FROM tb2 AS t2 WHERE t2.id = t.id); |
我在生成 Stmt 的时候就把所有的表和字段的别名全部替换成了真实的名字。
实现
语法分析部分就不赘述了。在生成 SelectStmt 中,我增加了 alias2name, name2alias, field_alias2name 这三个哈希表和 loaded_relation_names 这个列表(vector)。然后用于子查询会递归调用 SlectStmt::create() 方法,因此我们就中把上述四个变量作为参数传递即可。比如,在外层的 SelectStmt::create() 方法中,遍历并添加了 alias 和 name 的对应关系,紧接着是创建这个外层的 SelectStmt 的子查询,传递这些参数,那么这个子查询就能够根据传递进来的 alias 和 name 的对应关系来恢复真实的名字。这还有一个好处,即外层表也不会受到子查询的影响。
在最后我发现其实 MYSQL 不支持在 where 中使用别名,所以没必要将 field 的别名替换。
2
-- ERROR 1054 (42S22) at line 179: Unknown column 'num' in 'where clause'
具体来说:在 SelectStmt 中,会处理如下步骤:
- 初始化。检测 alias2name 等是否为空指针,如是则创建。
- 绑定表。遍历 loaded_relation_names,找到对应的表实例加入到当前 SelectStmt 的 table_map 中。通过这个方式加入的表都是外部的表,这里我还做了一个标记用来识别这个 table 是不是子查询中的 from 来的表。
- 遍历查询语句的 relations 以检查 alias 是否重复。
- 遍历查询语句的 relations,加入到 loaded_relation_names 中。并且,如果 alias 不为空,则还加入到
alias2name,name2alias(防止重复存到空的 alias 导致 duplicate error)。 - 遍历要查询的表达式,将其中的 alias 替换为真实的名字。这里需要递归处理。因为比如聚合表达式的子表达式才是真正的字段。如 SUM(t.id)。如果表达式是 StarExpr,并且有别名,直接报错。(*不允许有别名)。此外,如果该字段表达式有别名,则加入到 field_alias2name 中。
- 遍历 WHERE 子句中的条件,将其中的 alias 替换为真实的名字。这里需要递归处理。因为可能有子查询。
- 如果有子查询,在调用创建子查询的 create 方法中把当前的尚书的几个变量指针传递进去。
大体就是这样,还有一些小问题。
- 在处理类似
SELECT * from tb where id in (select value from tb2 where value > 1)这种子查询带有 WHERE 子句并且 Condition 的 Field 没有指定表的情况时,在绑定 UnboundFieldExpr 的时候,原本的代码是会报错的,因为此时要查询的表不只有一个,实际上还有来自外层查询的表tb。因此,我们必须将原本的逻辑“如果没有指定表并且要查询的表>1则报错”更改为遍历所有要查询的表。
1 | Table *table = nullptr; |
基本上就这样。对于字段的别名,最终要显示在表头,这个很简单不再赘述。
下面是在实现复杂子查询和别名时的提交 log:
发现复杂子查询要实现 OR,Alias 还有一个字段别名,并且简单子查询炸了,因为没考虑子查询没有使用外部表的情况。(这个问题在上面 简单子查询 一节中已经提及)
首先是 Alias 字段别名的问题:(在上面依然已经提及)
我们来整理一下:一开始是一个 UnboundFieldExpr,可能带有 alias。在bind_expression中会将其与表绑定,转换为FieldExpr。我们要做的工作是在 bind_expression 前将
- 主查询的 condition
- 子查询的 condition
中的可能使用了别名的字段(UnboundFieldExpr)中的 field_name 转为 真实的 field_name,将alias 转换为其 alias 即可,和处理 table 别名的情况类似。
接下来是 OR 的部分,我们新建一个对 OR 的语法解析,然后在 ConditionSqlNode 中加一个 conjunction_type,这里的类型我用了 char,节省空间。1byte!
然后在 FilterStmt 中加了一个 conjunciton_types 用于存储 where 查询字句中所有的 conjunction 连接符。然后在逻辑查询计划中据此确定用哪个。
这里我们只支持纯 AND 或者 纯 OR。
交一发!复杂子查询和简单子查询过了,alias 还有问题,update-select/vector_basic/vector_format/update 炸了。
真是炸炸又炸炸呀。
首先,来看看 vector_basic/vector_format,的炸点:
1 | SELECT C1, C2, L2_DISTANCE(C1, C2), L2_DISTANCE('[1,1,1]', '[1,2,3]'), COSINE_DISTANCE('[1,1,1]', C2) FROM TEST; |
OK,能够复现,convert_alias_to_name 由于刚刚修改了字段名,少了对 ExprType::VECTOR_DISTANCE_EXPR 的判断导致 static_cast 到 UnboundField 出错。
然后看看 update 的炸点:
1 | UPDATE update_table_1 SET t_name='1' WHERE id_false=72; |
猜测是不存在的 field 导致报错。事实也确实如此。在 bind_expression 当中,忘记写某个 field 没有找到 table 时的异常情况了。
交一发!结果是其他都解决了,还差一个 update_select_t2
1 | UPDATE Update_select_t2 SET t_name=52,col1=178.78 WHERE id=9; |
说实话,刚看到这个 diff 的时候有点不知所措。是什么原因呢 🤔?第二个 Update 语句要更新 t_name 为 Update_select_t1.col1 中的值,而这是个 int 类型,然而 diff 中显示会出现 3 | U0S6 | 3 | 8 这一列。int 类型还能是 U0S6?说明了什么?这条语句插入失败了,或者没有任何更新。那为什么没有出现 -FAILURE 或者 -SUCCESS 呢?如果暂且相信这个 diff,那说明 UPDATE 的输出结果至少是没问题的。注意到更新的是 id=3 的行,并且 id=3 有 3 个匹配的行,在这三行中,预期的输出是 col2=3,而有一行的输出是 col2=1。这给了我一个猜测——在更新到第一行匹配行的时候报错了,但是还是更新了。
让我们来看代码:
1 | while (OB_SUCC(rc = child->next())) { |
外层循环一行行的 tuple,内层根据要更新的字段表达式更新这一行的值。注意到了什么?更新某一个字段表达式的操作是可以被打断的——更新这一行的操作不是原子性的。让我们回到有问题的SQL,第一个 t_name 设置为等于一个子查询的返回值,但是如果这个子查询返回了多行呢,就会导致这个更新操作被打断,但是前面已经更新了 col1。
t_name 明明在 col1 前面,为什么会先更新 col1?可能的原因是在语法解析的时候由于递归特性,先解析了 col1 的表达式,但是没有 reverse。
我们只需要在外层循环中加一个 vector 存储这一行的所有更新操作,然后在循环结束后再执行即可。
修复之后,接下来还差 alias。
1 | select t1.id as num, t1.col1 as age, t1.feat1, t2.* from table_alias_1 t1, table_alias_2 t2 where t1.id < t2.id; |
直接给了一个failure。让我们看看怎么个事。
1 | miniob > select t1.id as num, t1.col1 as age, t1.feat1, t2.* from table_alias_1 t1, table_alias_2 t2 where t1.id < t2.id; |
在解析阶段就报了个错。少了一个 ID DOT ‘*’ 的情况。
那我们就在 rel_attr 处加一个这个情况,然后鉴于是 *,我们在 expresison 的语法树处做个简单的if判断,将其换为 StarExpr
测试一下,依然报错。
看了一下 DEBUG,原来少的是 relattr AS ID 的情况(漏了这里)
而 ID DOT ‘*’ 其实在代码层面有相关处理,因此不用在语法树解析做处理。
… 多次提测之后 …
1 | select count(*) as num, avg(t1.col1) score from table_alias_1 t1, table_alias_2 t2 where t1.id < t2.id; |
同样还是语法错误。
这让我反思,应该对整个 expression 的上级语法树节点 expressions 来加 AS ID 和 ID 比较好。而不是单单在 UnboundField 里面加。
最终,在 expressions 的语法树节点中加入了 ID AS ID 和 ID 的语法规则,并且把 alias 的存储直接放在了 Expression 抽象类中。成功过测。
Aggregation-And-GroupBy
我们只需要实现 having 子句。很容易可以想到在 select_stmt 中加一个 havings,类型是 Condition。
本质上还是筛选,我们只需要在 GROUP BY 算子后再加一个 Predicate 算子即可:对 GROUP BY 的结果进行筛选。
然而,需要注意的是,可能会有 SELECT name, SUM(score) from tb GROUP BY name HAVING COUNT(*) > 10; 这种情况。在 HAVING 子句中有一个聚合表达式,并且这个聚合表达式没有出现在查询表达式中。
在这种情况下,不可能单单仅靠 Predicate 来筛选了,因为聚合表达式需要对所有符合条件的 tuple 进行计算和聚合。而 Predicate 只是对 tuple 进行筛选。
这里,我的做法是把 Having 子句中所有聚合表达式全部交由 GROUP BY 管理,然后 GROUP BY 返回的 tuple 就会包含 真正要查询的结果和 HAVING 子句中的聚合表达式的结果。Predicate 就可以借此进行筛选。并且由于 Project 的存在,最终用户看到的只是真正要查询的结果。
实现方面很简单,只要修改逻辑算子和物理算子的相关代码即可。不赘述。
Create-Table-Select
要实现:
1 | CREATE TABLE tb1 AS SELECT * FROM tb2; |
这样的 SQL,即根据 SELECT 的结果创建表并将查询结果插入到新表中。
语法分析方面,在 CreateTableSqlNode 中加了一个 subselect 字段,用于存储查询语句。然后据此修改语法树。在 CreateTableStmt 的 create 方法中,如果 subselect 不为空,就调用 SelectStmt::create() 方法创建 SelectStmt。并写一个函数来将 SelectStmt 的查询表达式转换成 FieldMeta 列表,本质上是需要智能解析出要创建的表的列属性,当然,如果 CreateTable 已经指定了列的属性,就不用获取了。
在查询计划中,同样如果 subselect 不为空,就根据存好的 SelectStmt 创建查询的逻辑计划算子,然后创建物理查询算子存入 CreateTableStmt 中。在 CreateTableExecutor 中,创建好表之后,打开查询物理算子存入就好了。思想上很简单。
Create-View
需求分析
需要实现创建视图、插入视图、更新视图。并且需要着重考虑在多表、带 alias 的情况下,视图的插入和更新操作。
首先,测试了下 MySQL 的视图功能,发现以下几个要注意的点:
- 视图名不能和别的视图名、表名重复。(废话)
- 创建视图时会检查 SELECT 语句能够正常执行,包括表名、字段名、子查询等。也就是说需要正常走一遍 SELECT 查询计划,但不输出行结果。
- 视图和原始表同步更新,更新视图会更新原始表,更新原始表会更新视图。
- 带聚合的视图是 not insertable-into 的。[ERROR 1471]
- 对于 join view,那么表的字段名不能重复(即使指定定了表名),否则会报错。[ERROR 1060]
- 对于 join view,不能同时插入/更新两个表的数据。[ERROR 1394]
- 对于 join view 的插入/更新操作,需要指定的字段。[ERROR 1393]
- 视图的字段名是可以自定义的(fields list),这种情况下,会覆盖掉结果集的字段名。并且,fields list 的长度必须和结果集列数一致。[ERROR 1058]
需要注意的是,在 MYSQL 中,视图是虚拟表的存在,磁盘不会存储视图的任何 SELECT 的结果集,只会简单地存它的定义。INFORMATION_SCHEMA.VIEWS 中存储了所有的视图信息。这个表的结构如下:
1 | mysql> describe views; |
对于我们的实现来说,只需要保留 TABLE_SCHEMA, TABLE_NAME, VIEW_DEFINITION, IS_UPDATABLE 这几个字段即可。
NOTE: 在实现后期,发现还需要加一个
ATTRS_NAME字段,用于存储用户自定义的视图的字段名。
NOTE:下文的
视图定义指的是VIEW_DEFINITION字段中的内容。即视图的 SELECT 语句。
实现
View 类
为了在执行算子中表示一个视图,我们还需要创建一个 View 类。为了减小风险和侵入性,在我的设计中,我让 View 继承了 Table 类,其实这也说的通,View本质上就是一个临时表,应当具有表的所有属性。View 类中存储了:
1 | std::string view_name_; |
前四个就是 View 的基本属性,第五个是表的 ID。。后面几个是在实现插入、更新时的辅助信息,下面再进行阐述。
在打开数据库时,会初始化 Db 实例用于表示一个数据库实例,miniob 默认只有一个数据库,因此就只有一个 Db。在 Db 初始化时,会加载(Open)所有的表和视图信息。默认实现了 open_all_tables 方法,我仿照这个方法实现了 open_all_views,这个方法使用了 RecordFileScanner 扫一遍 __miniob_views__ 表(如果没有这个表就跳过),然后创建 View 对象加入到 unordered_map<string, View *> opened_views_ 中即可。view_id 从 114514 开始,每创建一个 View 递增 1。
由于继承了 Table,那么也会有 TableMeta 属性。视图的 TableMeta 属性就是 select 的结果集的 fields meta
创建视图
CREATE-VIEWS 的流程相对简单,类似于 CREATE-TABLE-SELECT 题目。如下:
语法解析- 创建一个
create_view_stmt,在create_view_stmt中创建 SELECT 的 Statement 对象。 - 创建 SELECT 的逻辑计划和物理计划,并且把创建好的物理计划指针存入
create_view_stmt。 create_view_executor中执行一遍存入的 SELECT 的物理计划算子,如果没有发生任何报错,则将视图信息插入到__miniob_views__表中(如不存在则创建)。这个表是我自定义的,专门用于存储视图信息。
在插入成功后,创建视图 View 对象,动态加入到 Db 的 opened_views_ 中,这样就不需要重新再从磁盘中读取视图信息了。
当然了,还需要注意视图的名字不能和视图、实体表重复。
对于 is_updatable 字段,如果视图描述中有聚合表达式等不正常的字段,就设为 0。
接着,修改了 Db 的 find_table 方法,如果找不到表,先去找视图。
查询视图
从这里开始,事情开始变得复杂了起来~
miniob 中处理 SQL 的阶段都放在一个函数 SqlTaskHandler::handle_sql(SQLStageEvent *sql_event) 中去实现,阶段包括
- parse_stage_: 解析 SQL 语句(语法分析)成
ParsedSqlNodes - resolve_stage_: 创建
Stmt - optimize_stage_: 创建算子
Operator,生成、优化逻辑计划,生成物理计划 - execute_stage_: 执行算子
这个函数的设计是用于处理一条 SQL 语句。而查询视图可不止需要处理一条,需要处理至少两条。一个是查询视图的 SQL,一个是视图定义,而查询视图的 SQL 中还可能会查询多个视图。比如 SELECT * from view_1, view_2; 就一共需要处理 3 条 SQL 语句。
一个视图对应一个视图定义,一次视图查询可能对应多个视图。
可见,查询视图操作需要进行多次 parse_stage_, resolve_stage_,optimize_stage_ 流程。因此我们不得不修改 SqlTaskHandler::handle_sql 函数。SQLStageEvent 贯穿了整个事件前端,为了方便,我把需要解析的视图定义、视图名字、视图 Stmt 都放在了 SQLStageEvent 中。由于有多个视图,因此这些都用 vector 存储。
在一次视图查询的解析阶段(parse_stage_)后,我们得到了要查询的视图名字,借此得到所有视图定义,把这些视图定义再进行 parse_stage_,得到 ParsedSqlNodes。存入 SQLStageEvent 中。
在 resolve_stage_,我们需要在创建视图查询 Stmt 前创建所有的视图定义的 Stmt,因为视图查询的视图也是 Table,需要先初始化其 table_meta(视图创建好后,是没有初始化它的 TableMeta 的,我设计的是在查询视图的时候才会初始化它的 TableMeta)。而 table meta 的初始化需要各字段的 FieldMeta,而字段信息只能在 Stmt 创建之后得到。
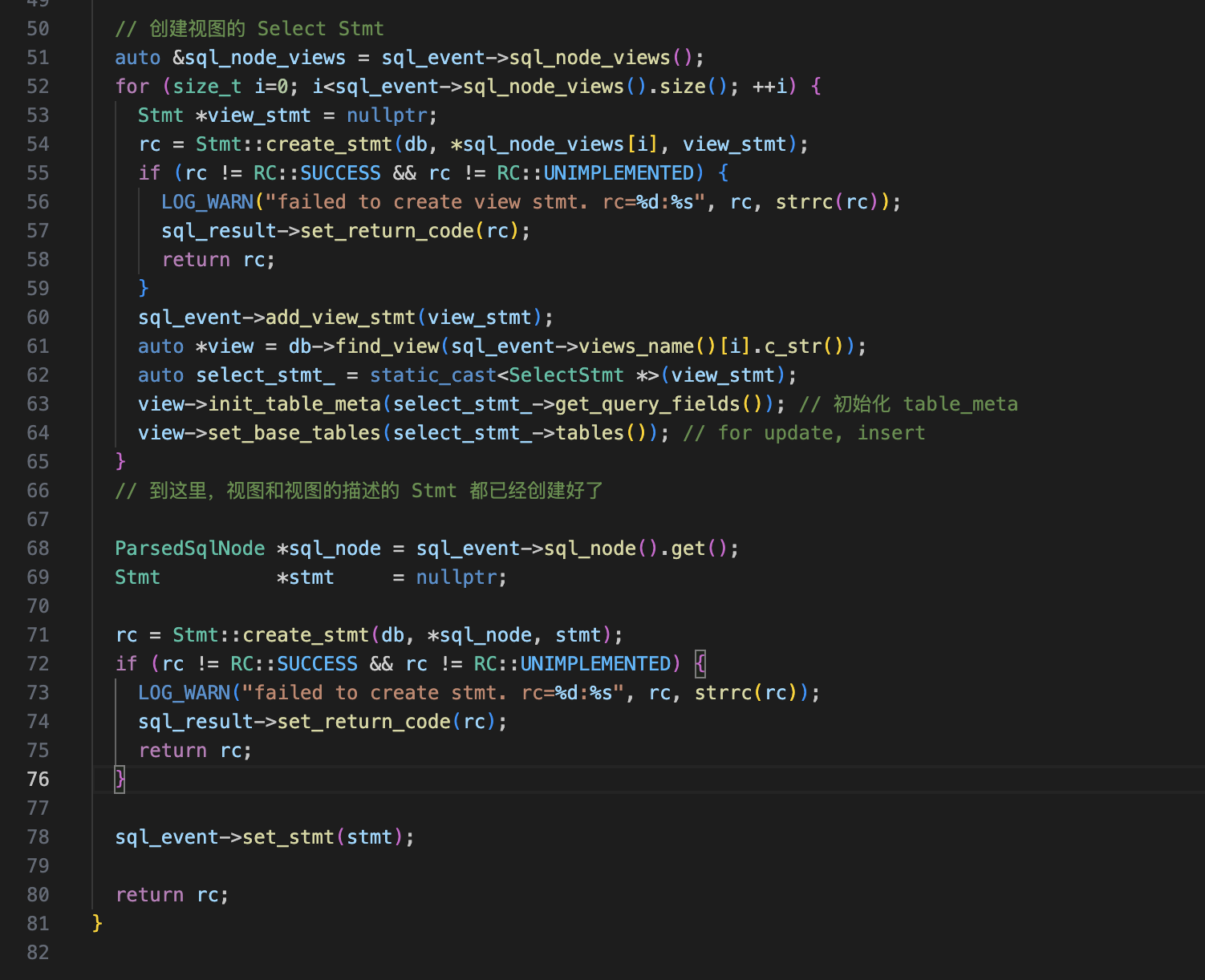
到了 optimize_stage_,我们需要通过 视图定义 的 Stmt 得到物理算子,然后放入视图的 operator_ 中。
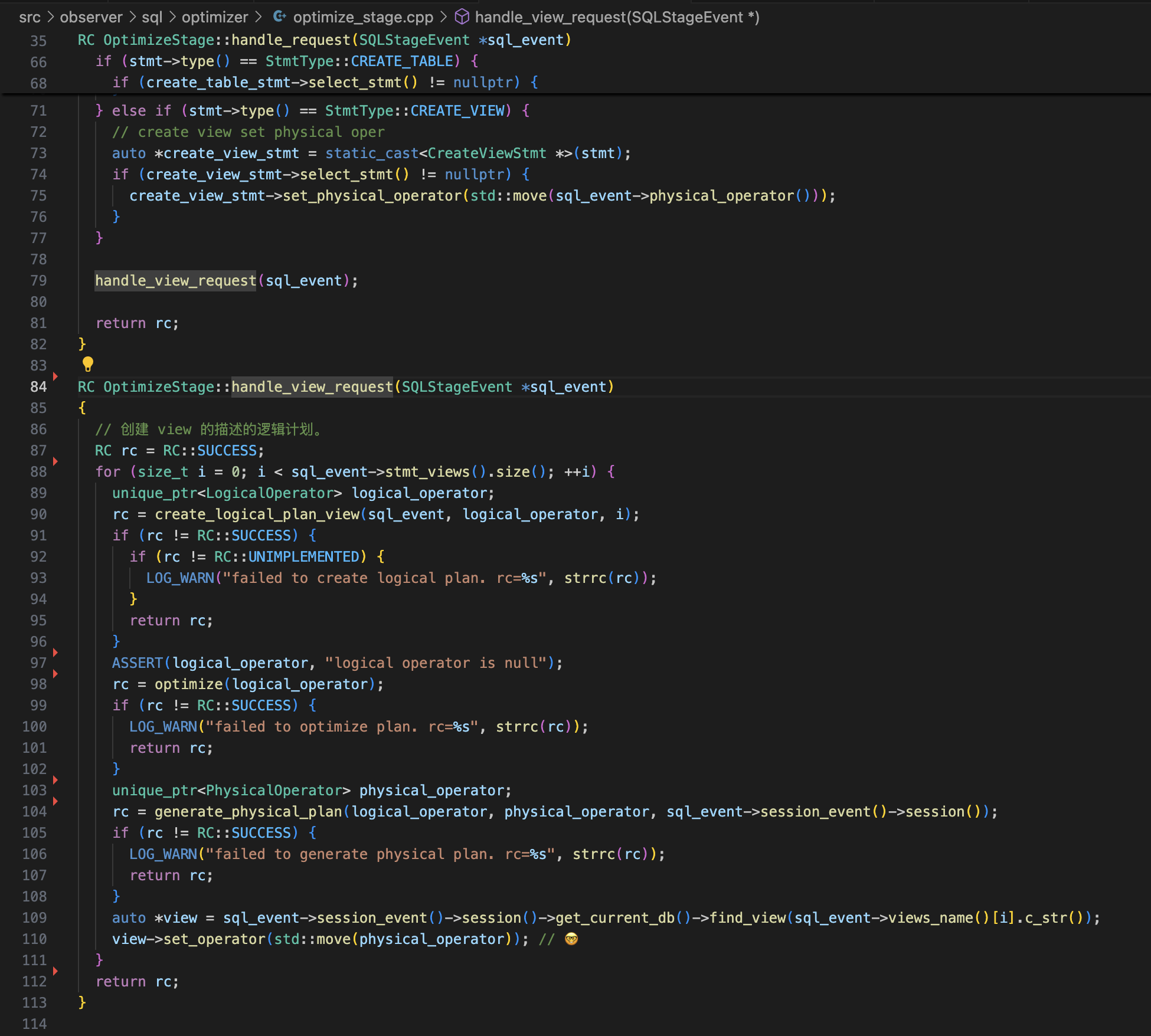
一切都很简单。
到了 execute_stage_,我们需要思考一下怎么查询视图。我想到了两个方案。一个是先调用视图定义的算子,把结果集全部取出来,存成一个临时表到磁盘,然后执行查询视图的计划就非常方便了。但是这个方法的一个很大的弊端是需要访问很多次磁盘,在结果集很大的情况下效率非常低。因此,我的第二个方法就是直接把两个计划的算子“拼接起来”。
在 miniob 中,最底层的算子永远是 TableScanPhysicalOperator,它调用 Table 实例的 FilePageScanner 来扫描出 Record 再转换成 RowTuple,最顶层的算子永远是 ProjectPhysicalOperator,它对下层算子的 Tuple 进行投影,转换成 ExpressionTuple。因此,我们的工作就是让 TableScanPhysicalOperator 对接上 ProjectPhysicalOperator。带有 Join 算子的场景会不会出问题呢?稍微画个图就知道其实没问题:
1 | (left)|->TableScan->[视图定义的]Project->... |
在 TableScanPhysicalOperator 中,需要调用 Table::get_record_scanner 获得 RecordFileScanner 对象,通过 RecordFileScanner::next(Record &record),以扫描表内的所有记录。RecordFileScanner 类很复杂,但需要读取表的 Page 文件。而 View 就是个虚拟表,哪来的实体文件?诶 🤓,很简单,这时候之前存的 View 中的 operator_ 就派上用场了,我创建了一个 RecordPhysicalOperatorScanner,它的 next 方法就是去调用这个 operator_ 物理算子。
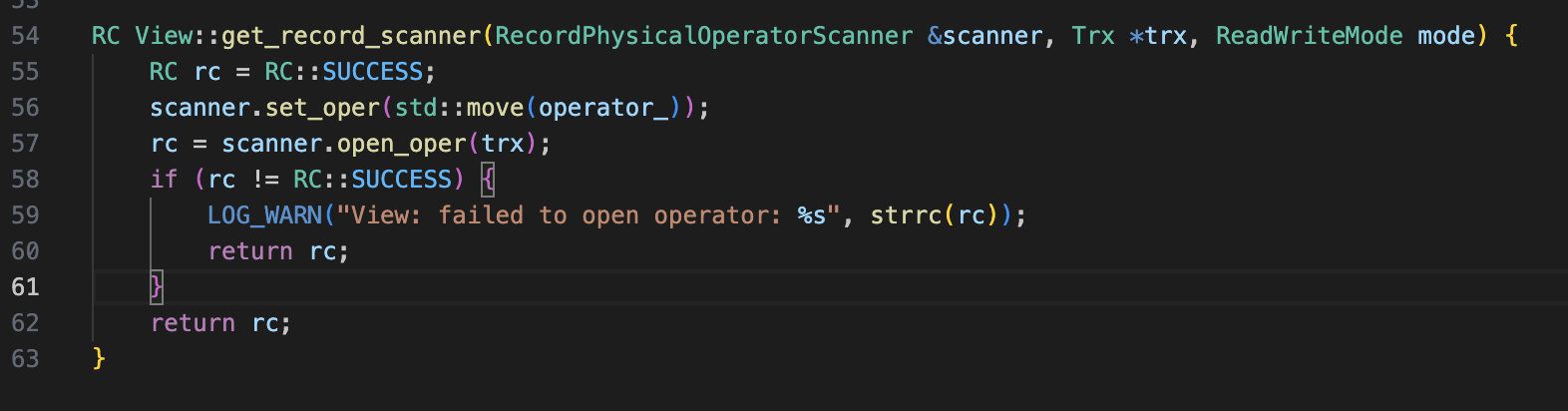

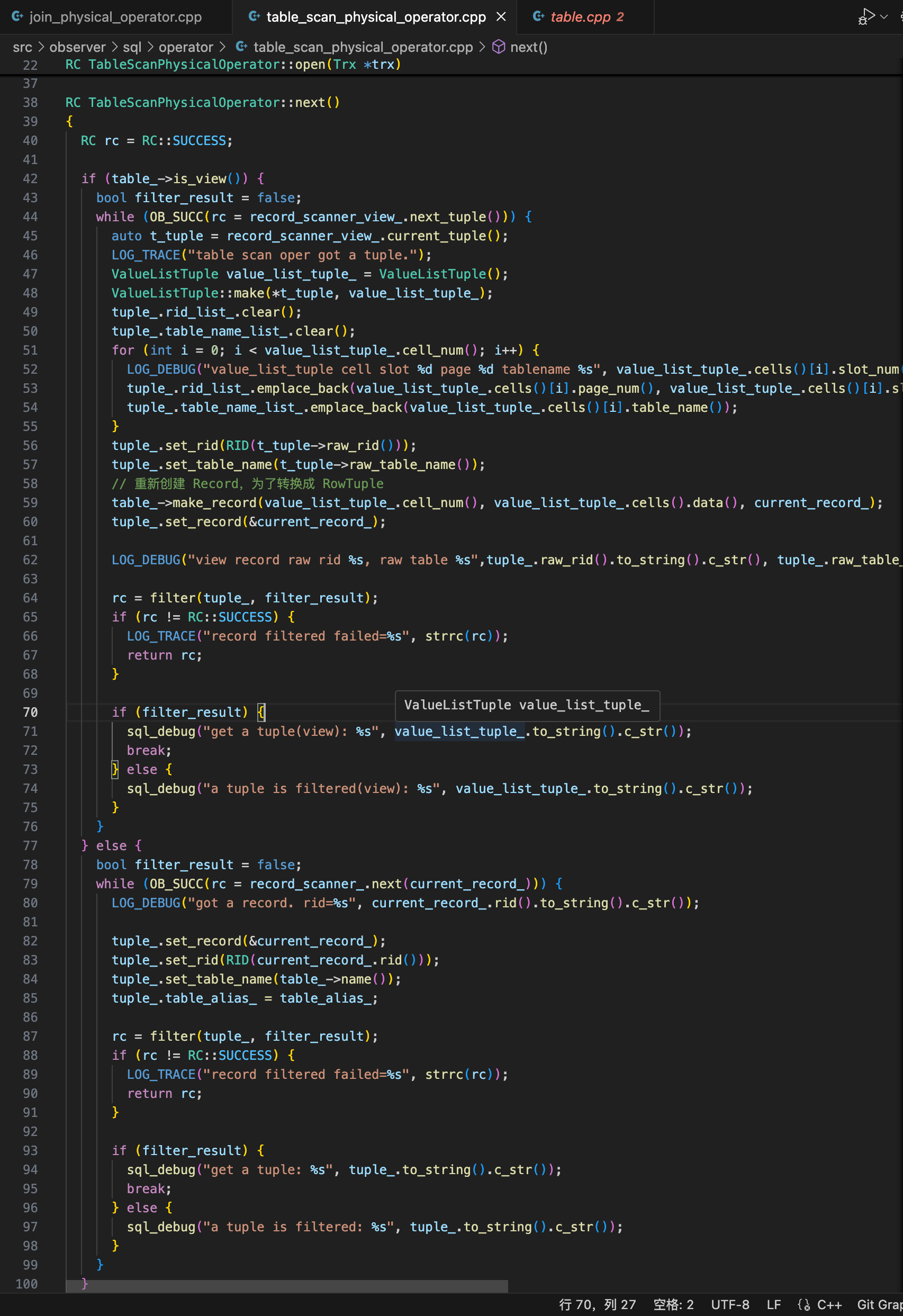
得到了 scanner 之后,就是在 TableScanPhysicalOperator::next() 中去调用这个 scanner 的 next 方法了。如果当前的表是 View,那么就用 RecordPhysicalOperatorScanner 得到 tuple。需要注意的是,这里的 Tuple 的类型我们是不知道的。
我本来打算直接转换成 ValueListTuple 然后共上层调用,但这样导致我在实现视图更新时,上层的 Update 算子无法得到 Record 的 RID 信息导致无法更新(这里踩了很久的坑),最后,我只能通过 ValueListTuple 来制作 Record 对象,然后通过 Record 对象又创建回 RowTuple。
1 | // while (OB_SUCC(rc = record_scanner_view_.next_tuple())) ... |
这样的一个好处就是统一了 Table Scan 算子输出的 Tuple 类型。
插入视图
插入视图有几大难点:
- 如果视图描述有 join,需要知道视图的某个字段属于哪个表。
- 如果视图描述中用到了别名,那么视图的字段名和表的字段名可能不一样,需要做映射。
- 插入语句也可以指定要插入的列的,比如
insert into view1(id, name) values (1, 'a')这种情况。此时需要大改 INSERT Stmt。(但是测试用例好像没有这个开,不过我还是按照这个思路去做实现了)
并且,MYSQL 对 JOIN View 的插入是有限制的:
- 不能同时插入两个表的数据。
- 插入的时候需要指定字段。
比如,有两个表 tb1 和 tb2 各有两个 int 列,视图 v1 的描述是 SELECT tb1.id, tb2.num FROM tb1, tb2;。
那么:
1 | INSERT INTO v1 VALUES (1, 2); -- X |
这时候,之前定义的 View 的 field_base_table_name 和 attr_name_2_base_table_field_name 就派上用场了。一个是用于判断字段属于哪个表,一个是在指定了视图字段名的情况下,找到对应的表字段名。这两个 map 都很好实现,这里不赘述。
Note: 1. 如果 attrs_name_ 不为空,说明视图的字段名是自定义的,并且长度严格等于 SELECT 的结果集的列数——这个是在创建视图就应该保证的。
2. 如果 base_tables_ 长度大于 1,说明视图是 join view。
在 Insert Stmt 中,做一些 Join View 的相关 fast-fail 检测。如果指定了插入的字段,那么存在 value list 长度不等于 view 字段长度的情况,miniob 原实现会导致 crash,这里需要做相关更改。
在 Insert 物理算子中,如果 attr_name_2_base_table_field_name 不为空,就通过 attr_name_2_base_table_field_name 找到原字段名,然后就可以找到对应的表。然后根据表的 Field Meta 列表,创建 Value List。这里注意 没指定插入的或者视图中没有但表中有的字段,需要设置为 NULL(如果原表字段设置了 nullable 为 false 就报错)。
MYSQL 不支持同时插入多表,但我这里额外实现了这个功能。很简单,在最外层循环套一个 base_tables_ 循环,然后对每个 base_table,根据 attr_name_2_base_table_field_name 和 field_base_table_name 找到对应的字段,创建 Value List 再进行插入操作即可。似乎不是很难,但很难理解为什么 MYSQL 不支持这个功能。
实现的过程中,犯了一个错误:
field_meta.table_name_ = *field_expr.table_name();
这里 table_name() 返回一个 const char *,我本来想解引用 field_expr,然后调用 table_name(),但是由于没加括号,导致 field_meta.table_name_ 取的是这个字符串的首地址,得到的是第一个字符。正确写法是field_meta.table_name_ = (*field_expr).table_name();或者field_meta.table_name_ = field_expr->table_name();。
更新视图
更新视图是整个视图实现中最复杂的部分。除了 Insert 上提到的字段映射的问题,还有一个比较棘手的问题:更新算子需要知道更新的这个 Tuple 的 RID 和 Tuple 所属的表名(不是视图名),然而除了 RowTuple 还持有 RID 之外,所有的 Tuple 都不存储这些信息。事实上,原来的 miniob 的更新算子中断言了它获取到的 Tuple 是 RowTuple(这也是上面在讲 TableScan 时为什么要转换回 RowTuple 的原因)。
字段转换的问题解决了,逻辑很复杂,但思想很简单,和上面插入视图本质上很像,不赘述了。那后面这个问题怎么解决呢?
一开始,思考了许久,我决定在 Tuple 上直接加一个 RID rid_ 和 std::string table_name_ 变量,在 TableScan 算子制作 RowTuple 时,更新这两个变量。这样就够使得所有 Tuple 都有这两个信息了。需要额外考虑一点,在高层的算子,比如 Order By、Predict,他们会重新创建 Tuple 会使得这两个信息丢失,因此在这些算子中,需要重新设置这两个信息。(这也是我思考了许久的原因,因为这样会改很多算子,我懒orz,一直在思考如何在改动最小的基础上加这个功能)。跑了一下,诶!怎么更新算子没在表中找到指定 RID 的记录?Debug 之后才发现是在写入 RID 的值时 page_num 和 slot_num 写反了。。修改之后,更新视图就可以正常运行了。
我本能地测试了一下 Join View,可惜的是,还是出问题了——还记得我们是如何实现视图查询算子和视图定义查询算子的连接的吗?先将视图定义查询算子传递的 Tuple 转换成 ValueListTuple,然后转换成 Record,最后再转换成 RowTuple。
问题出在这个转换过程,我们损失了所有我们自己加的信息,只保留了算子传递上来的 Tuple 中 cells 中的数据信息,导致 RowTuple 中的 Cells 可能来自不同的表。
这就有点棘手了。最后(也是没有办法的办法),我给 cell,也就是 Value 类都加上了这两个信息,也就是直接把粒度放到了最小。
然后在 RowTuple 中,再单独开了 rid_list_ 和 table_name_list_ 在转换成 ValueListTuple 之后,把其中的 cell 中的 RID 和 table_name 都写入到这两个 list 中。这样,Update 算子就能知道这个 RowTuple 中各个 Cell 的 RID 和 table_name 了。
总结
在实现视图中,时刻需要注意当前 table 的 table_name 是视图的 table name 还是视图定义中表的 table name,别看这两个相差很远,实际上在写功能的时候很容易弄混淆。此外,还需要注意字段名,对应关系一定要存清楚。明确创建视图的 field_list 和视图定义中的表和表中的 fields 的对应关系。
1 | 1. 视图中的 table_meta 中的 field_meta 的列名的来源是:创建视图的field_list > 视图定义的查询字段别名 > 视图定义的查询字段名。其中创建视图的field_list要给就全部给完,不能只给一部分。因此 View 的 attr_list 要么为空,要么其长度等于视图定义的查询字段数。 |
此外,记忆犹新的一个测试用例是 create view v1 as select * from tb1 t1, tb1 t2 where t1.id = t2.id;,特殊在它 join 的表是同一个表。这导致我的代码 join 出来的结果和实际的结果不一样(甚至不是视图的问题),debug 之后意识到我在 select_stmt,也就是上层就把所有的 alias 给替换成了真实的表名,导致底层的 predicate 算子分不清 join 传上来的 tuple 中的 cell 的字段来自于哪个表。这又得让我重新把 table_alias 从上层传到底层。。太搞人心态了。
最后,在重复提测好几次之后,在 2024 年 11 月 8 日 01:37 分通过了这重量级的一题。wakatime 上显示我在实现这个分支上花了 30 小时。